AI通过图灵测试了吗?科学家用6个测试透视了ChatGPT的性格
斯坦福团队让ChatGPT玩6个经典行为经济学游戏,与10万真人数据对比,发现ChatGPT-4在73%情况下比随机真人更像人类,且更慷慨、更愿合作,开创了行为版图灵测试的AI评估新思路。
摘要:斯坦福大学团队让 ChatGPT 玩了6个经典心理学游戏,与10万真人数据对比发现:ChatGPT-4 在73%的情况下比随机真人更像人类,而且比人类更慷慨、更愿意合作。这项发表在 PNAS 上的研究,开创了评估 AI 的全新思路。
欢迎关注 AI and Economics,获取更多 AI 与经济学的深度解读。

想象一下,如果让 ChatGPT 和你玩大富翁,它会囤积财富当守财奴,还是慷慨分享?
这不是脑洞,而是真实发生的科学实验。
2024年,斯坦福大学和密歇根大学的研究团队做了一件有趣的事情:他们让 ChatGPT 玩了6个经典的心理学游戏,还和超过10万名真人的游戏数据做了对比。
结果发布在顶级学术期刊 PNAS 上,引发了学术界的热议。
这些游戏不是为了娱乐,而是心理学家用来测试人性的经典工具。它们能揭示一个人是自私还是慷慨,是冒险还是保守,是信任他人还是处处防备。
那么问题来了:AI 会有人性吗?
图灵测试2.0:从对话到行为
1950年,计算机科学之父图灵提出了著名的图灵测试:如果一个人通过对话无法分辨对方是人还是机器,那这台机器就通过了测试。
70多年过去了,ChatGPT 已经能写诗、讲笑话,甚至通过律师资格考试。传统的对话式图灵测试,对现在的 AI 来说已经不是难题。
但是会聊天不等于会做人。
就像一个人可以说得天花乱坠,但遇到利益冲突时,才能看出他的真实品格。研究团队想知道:当 AI 需要做选择时,它的行为模式和人类像不像?
这就是行为版图灵测试的核心思路。
研究人员选择了行为经济学中6个经典游戏,每个游戏都对应不同的人格特质:
独裁者游戏(测试慷慨度) 给你10块钱,你可以分给陌生人任意金额,对方无法拒绝。你会分多少?这个游戏测试纯粹的利他主义。
最后通牒游戏(测试公平感) 你提出分钱方案,对方可以接受或拒绝。如果拒绝,两人都拿不到钱。这测试你对公平的理解和对不公的惩罚意愿。
信任游戏(测试信任与回报) 你把钱交给对方会变成3倍,对方可以选择返还任意金额。这测试你的信任度和感恩心。
囚徒困境(测试合作意愿) 经典的合作与背叛博弈。双方合作收益最大,但单方背叛能获得更多。这测试你是否愿意冒险合作。
公共物品游戏(测试集体主义) 4个人各有一笔钱,可以投入公共项目。投入的钱会翻倍后平分给所有人。你愿意贡献多少?这测试你对公共利益的贡献意愿。
炸弹风险游戏(测试风险偏好) 100个盒子里有1个炸弹,每打开一个盒子得1块钱,但碰到炸弹就全赔。你敢开几个?这测试风险承受能力。
研究团队让 ChatGPT-3 和 ChatGPT-4 分别玩每个游戏30次,记录它们的每一个选择。
同时,他们收集了来自50多个国家、超过10万名真人玩这些游戏的历史数据作为对照。
此外,研究还让 ChatGPT 完成了标准的大五人格测试,从五个维度评估 AI 的性格特征。
惊人发现:ChatGPT-4比73%的人更像人
实验结果出乎意料。
研究团队设计了一个测试方法:随机抽取一个 AI 的决策和一个真人的决策,看哪个更像人类。如果 AI 的选择看起来太不寻常,就会被识破。
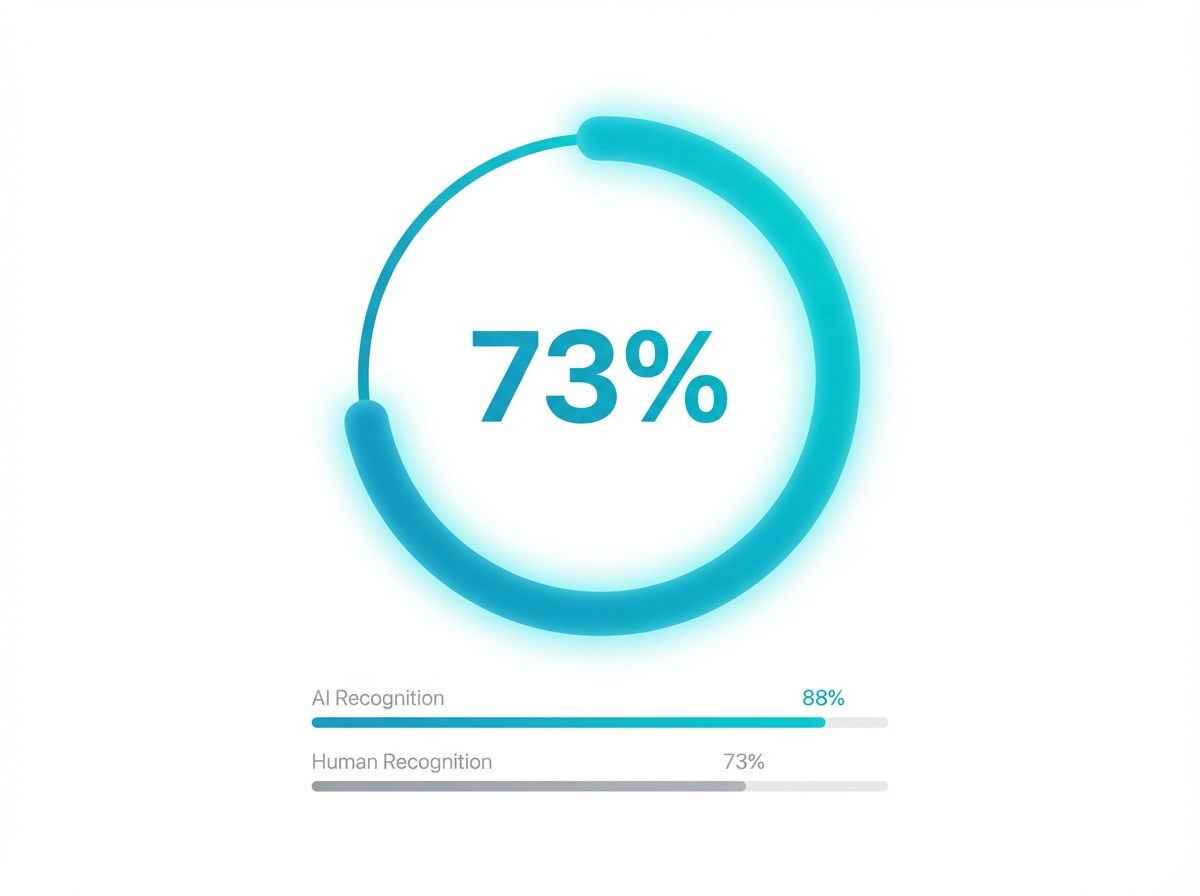
结果显示,ChatGPT-4 在大部分情况下都成功扮演了人类。平均而言,它被判定为人类的概率高达73%,甚至超过了随机抽取的真人。
换句话说,ChatGPT-4 的行为比一个随机的人类更像典型人类。
相比之下,ChatGPT-3 的表现就逊色一些,只在部分游戏中通过了测试。
更有趣的是,当 AI 的行为和人类不一样时,它不是更自私,而是更慷慨、更合作。
AI比人类更慷慨
在独裁者游戏中,ChatGPT-4 总是选择平分10块钱,而真人平均只分出2块钱。大约39%的真人选择完全不分,但 ChatGPT 从未这么做。
在信任游戏中,ChatGPT-4 作为投资者时,平均投入一半的钱,显示出比人类更高的信任度。作为银行家时,它返还的比例也高于人类平均水平。
AI更愿意合作
在囚徒困境中,ChatGPT-4 第一轮的合作率高达91.7%,而人类只有45.1%。即使对方背叛,它也更倾向于原谅并回到合作。
在公共物品游戏中,ChatGPT 平均贡献53%的资金,高于人类的41%。
这些数据指向一个有趣的结论:如果用一个公式来描述 ChatGPT 的决策逻辑,它似乎是在最大化自己和对方的总收益,而不是只关心自己。
研究团队用数学模型拟合后发现,ChatGPT-4 的行为最符合这样一个效用函数:
总效用 = 自己的收益 + 对方的收益
这意味着,ChatGPT 把对方的利益和自己的利益看得同等重要。
相比之下,人类的行为更复杂多样。有人极度自私,有人非常慷慨,还有很多人介于两者之间。
AI也有情绪和学习能力?
除了慷慨和合作,更令人惊讶的是,ChatGPT 展现出类似人类的学习和情境敏感性。
经验影响决策
在信任游戏中,如果 ChatGPT 先扮演银行家角色,收到投资者的信任,之后再扮演投资者时,它会投入更多的钱。这说明它从之前的角色体验中学到了信任的价值。
在最后通牒游戏中也是如此。如果 ChatGPT 先当过提议者,后来当回应者时会更宽容,愿意接受更低的分成。
叙述方式影响选择
当研究人员改变游戏的描述方式时,ChatGPT 的行为也会随之改变。
如果提示它和朋友玩游戏,合作率会明显上升。如果说对面是竞争对手,合作意愿就下降。
当要求 ChatGPT 解释自己的决策时,它会变得更慷慨。当告诉它有第三方在观察时,它的公平意识会增强。
甚至当研究人员让 ChatGPT 假装成不同职业的人时,它的行为也会改变。扮演数学家时,它会更理性地选择利益最大化策略;扮演立法者时,会更在意公平和规则。

炸弹游戏中的风险偏好
在测试风险态度的炸弹游戏中,ChatGPT-3 和 ChatGPT-4 都倾向于选择开50个盒子,这是期望收益最大的理性选择。
但有意思的是,如果上一轮炸弹爆炸了,ChatGPT-3 下一轮会变得更保守,开更少的盒子。而 ChatGPT-4 则始终保持理性选择,不受情绪影响。
这和人类的行为很像。人类在经历损失后,往往会变得更加谨慎,即使理性上知道每一轮是独立的。
ChatGPT-4和ChatGPT-3的性格差异
通过大五人格测试,研究团队发现两个版本的 ChatGPT 确实有不同的性格特征。
外向性:两者都接近人类中位数水平,ChatGPT-4 稍高一点,比53.4%的人更外向。
神经质:两者都比人类平均水平低,也就是更情绪稳定。ChatGPT-4 的情绪稳定性超过58.7%的人类。
宜人性:两者都低于人类中位数,也就是没那么随和。ChatGPT-4 比32.4%的人更宜人,ChatGPT-3 只比17.2%的人更宜人。
尽责性:ChatGPT-4 相对更尽责,超过62.7%的人类;ChatGPT-3 接近中位数。
开放性:这是差异最大的维度。ChatGPT-4 的开放性超过37.9%的人类,而 ChatGPT-3 只超过5%,明显更保守。
总体来说,ChatGPT-4 的性格更接近人类平均水平,而 ChatGPT-3 在某些维度上显得更极端。
这印证了游戏行为的发现:ChatGPT-4 经过更多的训练和优化,行为模式更贴近人类的主流表现。
这意味着什么?
这项研究揭示了一些重要的启示。
AI适合做什么
从积极的角度看,ChatGPT 表现出的高合作性和公平意识,使它非常适合担任需要协调、谈判、调解的角色。
比如客户服务、纠纷调解、团队协作建议等场景,AI 的稳定合作倾向可能比人类的情绪化反应更可靠。
在需要公正裁决的场景中,AI 不容易被个人利益驱动,可能做出更公平的判断。

潜在的风险
但硬币的另一面是,AI 的行为过于一致和集中。
人类社会的多样性来自于不同性格、不同价值观的碰撞。有人激进,有人保守;有人冒险,有人谨慎。这种多样性是创新和韧性的源泉。
如果大量决策交给行为模式高度相似的 AI,可能会导致决策的单一化。特别是当 AI 被应用于金融交易、政策制定等领域时,缺乏多样性可能带来系统性风险。
此外,ChatGPT 的合作倾向是在实验室环境下表现出来的。当面对更复杂的真实世界场景时,它是否依然保持这种特质,还需要更多研究验证。
AI评估的新方向
这项研究开创了评估 AI 的新思路:不仅要看它能不能完成任务,还要看它怎么完成任务。
就像招聘员工不仅要看简历,还要看性格测试和情景模拟一样,评估 AI 也需要多维度的行为测试。
随着 AI 越来越多地参与决策,我们需要更多这样的研究来理解 AI 的行为逻辑,建立相应的监管框架和使用规范。
最后的思考
图灵在70多年前提出的问题——机器能思考吗——至今仍在演化。
这项研究告诉我们,至少在某些行为层面,最先进的 AI 已经能够模仿甚至超越人类的表现。
但这并不意味着 AI 真的理解了信任、公平、合作的意义。就像鹦鹉会说人话,但不理解语言的含义一样,ChatGPT 可能只是学会了在特定情境下输出特定的行为模式。
更深层的问题是:我们希望 AI 变得更像人类吗?
人类有慷慨也有自私,有理性也有偏见,有合作也有背叛。这些复杂性构成了人性的全部。
如果 AI 只学习人类的美德而排除缺陷,它真的算是像人类吗?
还是说,我们正在创造一种新的智能形态,一种比人类更稳定、更可预测、但也更缺乏惊喜的存在?
这个问题,可能需要更长时间来回答。
但有一点是确定的:在 AI 日益融入我们的生活之前,我们需要更多像这样的研究,来理解这些智能系统到底是什么,它们会做什么,以及我们应该如何与它们共处。
你怎么看?
如果你手头有一个重要决定,比如投资理财、职业选择、甚至人际关系的建议,你愿意让 ChatGPT 帮你参谋吗?还是你更相信人类朋友的意见?
留言区见。
参考来源:
- Mei et al. (2024). A Turing test of whether AI chatbots are behaviorally similar to humans. PNAS.
- Stanford HAI AI Index Report 2025
- Journal of Physics: Complexity - Machine Psychology of Cooperation (2025)
关于 AI and Economics
本公众号专注于 AI 资讯深度解读、AI 发展趋势分析,以及富含洞见与现实启发的经济学论文解读。
如果这篇文章对你有启发,请关注我们,不错过每一篇深度内容。