16.2 Skill 配置与项目初始化
面向经管学生、研究者与从业者的 AI 智能体设计教材
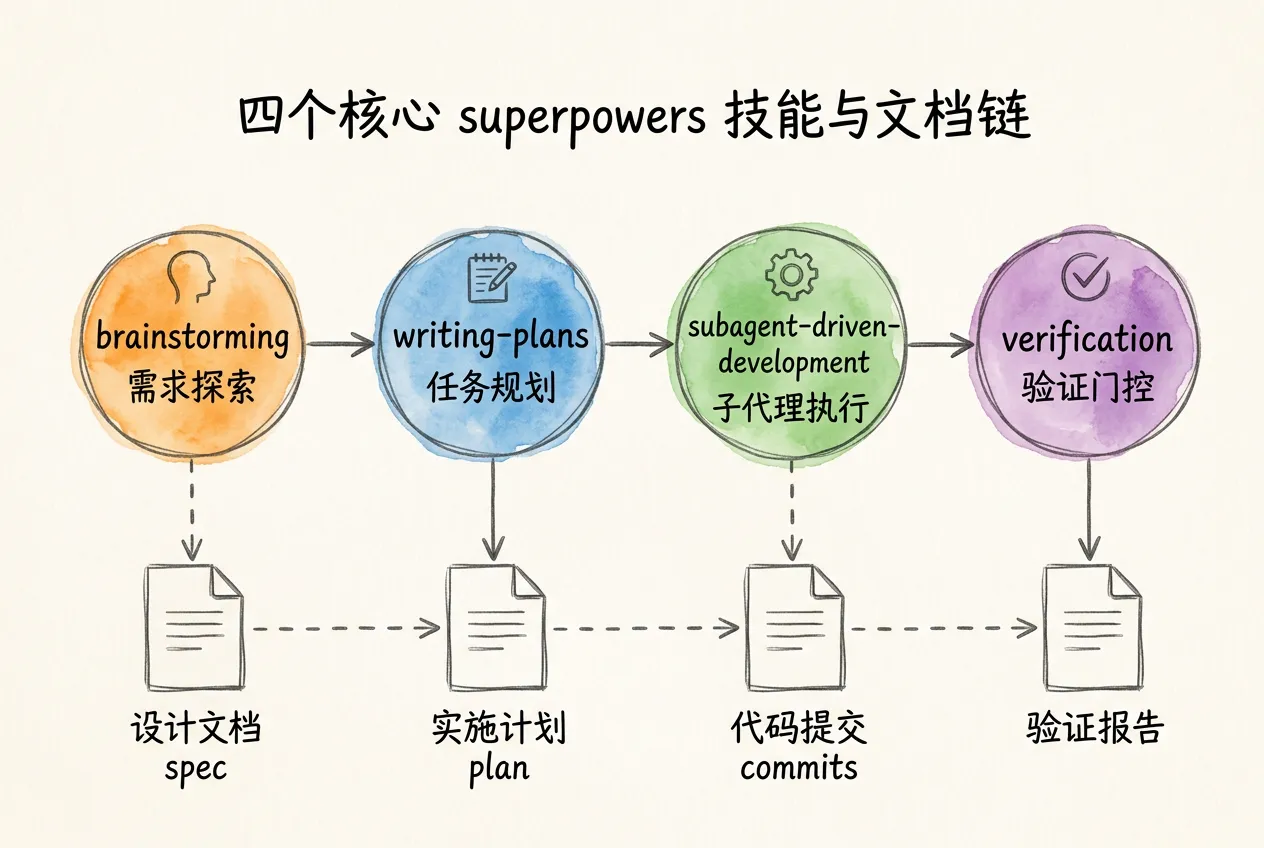
六阶段工作流中,每个阶段都有对应的 Skill 提供方法论和质量约束。本节完成两件事:配齐 Skill 工具链,搭建项目目录。
Skill 映射
superpowers(https://github.com/obra/superpowers)是一套面向完整开发生命周期的 Skill 集合,覆盖从需求探索到交付验证的全链条。本章选用其中 4 个核心 Skill 作为主干:
| 阶段 | Skill | 功能 | 文档产出 |
|---|---|---|---|
| 给需求 → 明确需求 | brainstorming | 引导式需求探索,产出设计文档 | docs/superpowers/specs/*.md |
| 制定更新计划 | writing-plans | 将设计文档转为分步任务计划 | docs/superpowers/plans/*.md |
| 执行代码迭代 | subagent-driven-development | 逐任务派发子代理,含双阶段审查 | 代码 commits |
| 验证门控 | verification-before-completion | 验证所有声明,拒绝未经测试的交付 | 验证输出 |
注意表格最后一列——每个阶段都有明确的文档产出。这条 spec → plan → commits 的文件级传递链是 superpowers 的核心设计。
superpowers 还包含 3 个辅助 Skill,在特定场景下按需使用:
| Skill | 功能 |
|---|---|
| requesting-code-review | 标准化代码审查,按 git diff 审查变更 |
| systematic-debugging | 四阶段根因调查,强制先定位再修复 |
| finishing-a-development-branch | 分支收尾:验证 → 选择处置方式 → 清理 |
mattpocock/skills(https://github.com/mattpocock/skills)提供代码库调研(grill-with-docs)和测试驱动开发(tdd)等工程实践工具。ui-ux-pro-max(https://github.com/nextlevelbuilder/ui-ux-pro-max-skill)提供前端设计系统智能。本章选择 superpowers 是因为它的文档链最完整——每阶段产出文档供下游读取,适合教学展示。如果你的项目有专门的代码库调研或前端设计需求,可以从这两个仓库按需补充。
文档链:阶段之间如何衔接
superpowers 的各 Skill 不是孤立的工具,而是通过文件建立上下游关系:
/brainstorming与用户对话后产出设计文档(spec),commit 到docs/superpowers/specs//writing-plans读取 spec 文件,将需求拆解为实施计划(plan),commit 到docs/superpowers/plans//subagent-driven-development读取 plan 文件,提取 Task 清单,逐任务派发子代理执行,每个任务的代码变更单独 commit
每阶段的产出都是持久化文件,下阶段的 Skill 直接读取文件开始工作。这种文档化实践带来两个好处:决策过程可追溯,任何阶段都可以独立回退和重做。
这是 superpowers 的核心链条。brainstorming 产出 spec,writing-plans 读取 spec 产出 plan,subagent-driven-development 读取 plan 逐任务执行。如果某个阶段的产出不符合预期,修改对应文件后重新触发下游 Skill 即可。
获取与安装
superpowers 的各 Skill 是独立目录,直接复制到项目的 .claude/skills/ 即可。部分 Skill 除 SKILL.md 外还包含附属文件(如 implementer-prompt.md、spec-reviewer-prompt.md),需一并复制。
安装完成后的目录结构:
.claude/skills/
├── brainstorming/ # 需求探索
│ ├── SKILL.md
│ └── visual-companion.md
├── writing-plans/ # 任务规划
│ └── SKILL.md
├── subagent-driven-development/ # 子代理执行
│ ├── SKILL.md
│ ├── implementer-prompt.md
│ ├── spec-reviewer-prompt.md
│ └── code-quality-reviewer-prompt.md
├── verification-before-completion/ # 验证门控
│ └── SKILL.md
├── requesting-code-review/ # 代码审查
│ └── SKILL.md
├── systematic-debugging/ # 根因调试
│ ├── SKILL.md
│ └── root-cause-tracing.md
└── finishing-a-development-branch/ # 分支收尾
└── SKILL.md手动复制安装的 Skill 用 /skill-name 触发(如 /brainstorming、/writing-plans),无需命名空间前缀。
项目目录结构
findata-kb/
├── .claude/
│ ├── skills/ # Skill 文件(见上方)
│ └── settings.json # Claude Code 项目配置
├── CLAUDE.md # 项目规则文件
├── docs/
│ └── superpowers/
│ ├── specs/ # brainstorming 产出的设计文档
│ └── plans/ # writing-plans 产出的实施计划
├── src/
│ ├── app/ # Next.js 前端页面
│ ├── components/ # UI 组件
│ ├── lib/ # 后端逻辑与 API 路由
│ └── tests/ # 测试文件
├── data/
│ ├── reports/ # 研报 PDF
│ ├── earnings/ # 财报数据(Excel/CSV)
│ └── news/ # 新闻与公告
├── package.json
└── .gitignoredocs/superpowers/ 存放 brainstorming 和 writing-plans 的产出物——设计文档和实施计划都自动保存在这里,形成可追溯的决策记录。
CLAUDE.md 配置
CLAUDE.md 是 Claude Code 在所有后续操作中遵循的行为锚点。以下是项目启动时的基础配置:
# 金融多源知识库(FinData-KB)
## 项目概述
多源金融数据知识库查询系统。支持导入研报 PDF、财报 Excel、新闻 RSS,
提供语义检索和智能问答功能。面向券商研究部门和买方分析师。
## 技术栈
- 前端:Next.js 15 + Tailwind CSS + shadcn/ui
- 后端:Next.js API Routes + Python(数据处理脚本)
- 向量数据库:ChromaDB(本地开发)/ Milvus(生产环境)
- 嵌入模型:Ollama qwen3-embedding:0.6b,维度 1024
- 文档解析:Marker(PDF/DOCX → 结构化分块)
## 目录结构
- src/app/ Next.js 前端页面(App Router)
- src/components/ 可复用 UI 组件
- src/lib/ 后端逻辑、API 调用、数据处理
- src/tests/ 测试文件,与源文件同名加 .test 后缀
- data/ 原始数据文件(不纳入 Git)
- docs/ 设计文档和实施计划(纳入 Git)
## 开发规范
### Commit Message
格式:<type>: <description>
类型:feat / fix / refactor / docs / test / chore
示例:feat: 添加研报 PDF 导入功能
### 分支策略
- main:稳定版本
- dev:日常开发
- feat/<name>:功能分支,完成后合并到 dev
### 测试
- 每个新功能必须有对应测试
- 子代理内置 test-driven-development,遵循红绿重构循环
- 运行测试:npm test
## Skill 使用指引
- 新功能开发:先 /brainstorming 完成设计 → /writing-plans 生成计划
→ /subagent-driven-development 逐任务执行
- Bug 修复:/systematic-debugging 定位根因后修复
- 完成声明:/verification-before-completion 要求先跑验证再声明完成
- 代码审查:/requesting-code-review 按 git diff 审查变更
## 数据规范
- 研报元数据:标题、作者、机构、发布日期、行业分类
- 财报元数据:公司代码、报告期、报表类型
- 分块参数:512 tokens,50 tokens 重叠
- 向量维度:1024(与嵌入模型一致,不可更改)项目启动时写好技术栈和目录结构即可。开发过程中,每次遇到 Claude Code 行为不符合预期,优先检查 CLAUDE.md 是否缺少约束,随时补充。
MCP 与 Git 初始化
端到端测试阶段需要用 Playwright 操控真实浏览器,先配置 MCP:
claude mcp add playwright npx @playwright/mcp@latestSkill 和配置文件就位后,初始化版本控制:
帮我初始化 Git 仓库。.gitignore 排除 node_modules/、data/ 目录、.env 文件。做首次提交,message 用 "chore: 项目初始化与 Skill 配置"。项目目录、规则文件、Skill 工具链、版本控制全部就位,可以进入需求探索阶段。