19.1 什么是 AI 原生知识管理
面向经管学生、研究者与从业者的 AI 智能体设计教材
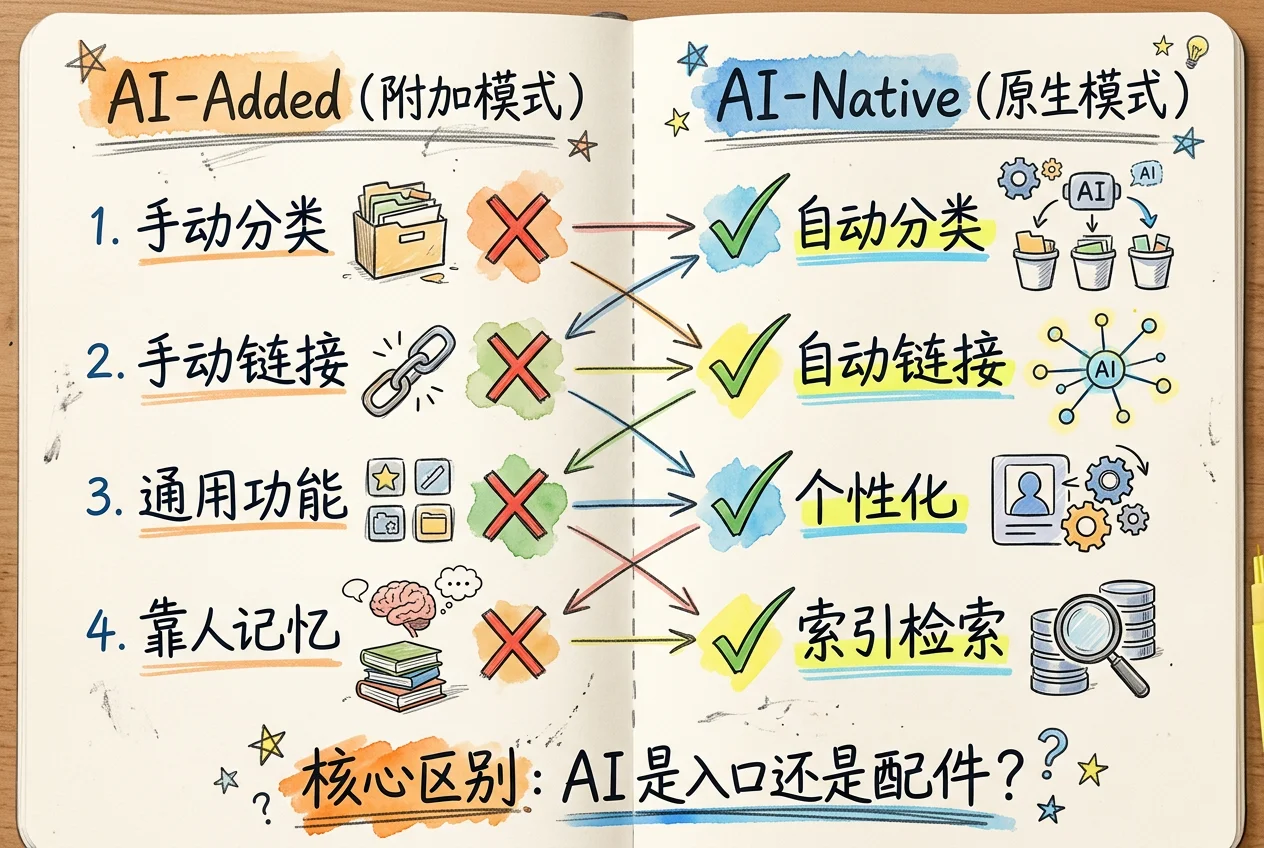
市面上很多笔记工具开始加入 AI 功能。你可以在笔记旁边打开一个聊天框,问它问题,让它帮你总结。但分类、归档、建链接,大部分操作仍需手动完成。
这是 AI-Added(AI 附加)模式:在现有工具上叠加 AI 能力。
AI-Native(AI 原生)模式完全不同。你输入一段内容,AI 判断它是什么类型,搜索已有笔记,整理成规范格式,放进正确的文件夹,更新索引。全程不需要你手动归类。更关键的是,它认识你——知道你的研究方向、当前项目和写作偏好,同一段输入在不同人的知识库中处理结果不同。
两种模式的核心差异:
| 特征 | AI-Added | AI-Native |
|---|---|---|
| 分类 | 手动操作 | AI 自动判断 |
| 连接 | 手动建链接 | AI 搜索并建立 |
| 个性化 | 通用功能 | 了解用户背景 |
| 记忆 | 靠人记 | 索引检索,不丢失 |
| 进化 | 功能固定 | 越用越准 |
传统笔记加聊天框为什么不够? 三个根本限制:
第一,聊天框只能回答问题,不能主动归档、建链接、更新索引。你问一个问题,它回答完即结束,不会把这次对话的收获写进你的知识库。
第二,每次对话是孤立的。上一次聊了什么,下一次不知道。没有持续的项目记忆。
第三,它不认识你。不知道你是做行为博弈论研究的还是做量化交易的,无法做个性化判断。
AI-Added 指在已有产品上叠加 AI 功能,如 Notion AI、飞书智能助手。AI-Native 指从架构层面就以 AI 为核心设计的系统,AI 参与每一步流程。
Claude Code 作为知识管理入口的独特优势
Claude Code 能胜任这个角色,因为它具备四个条件:
- 本地文件读写。直接操作你电脑上的文件,不依赖云端 API 中转。笔记就是普通 Markdown 文件,存在你的硬盘上。
- 自动读取 CLAUDE.md。每次启动对话,Claude Code 会读取项目根目录的
CLAUDE.md,按照里面的规则工作。这份文件是整套系统的控制中枢。 - Skills 标准化入口。通过
/takenote这样的 Skill 命令,每次记笔记的流程都是稳定、可重复的,不会因为你换了一种说法就产生不同结果。 - Markdown 不锁定平台。所有笔记都是纯文本文件,可以用 Obsidian 浏览,可以用 VS Code 编辑,可以用任何云同步工具备份。换工具不丢数据。
在用 AI 完成具体任务之前,先投资搭建基础设施。这不是拖延,而是战略选择。没有基础设施,每次 AI 交互都是孤立事件,用完即弃。有了 AI 原生知识库,每次交互都自动沉淀为可复用的知识资产。前期花几小时搭建,后续每天都能获得积累收益。
对经济金融研究者来说,这个原则尤其重要。一个研究周期动辄半年到一年,期间产生的文献笔记、数据发现、会议讨论、审稿意见如果没有系统沉淀,到写论文时就要从头翻找。搭好基础设施,这些碎片会自动积累成结构化的研究资产。