21.6 安全提示
面向经管学生、研究者与从业者的 AI 智能体设计教材
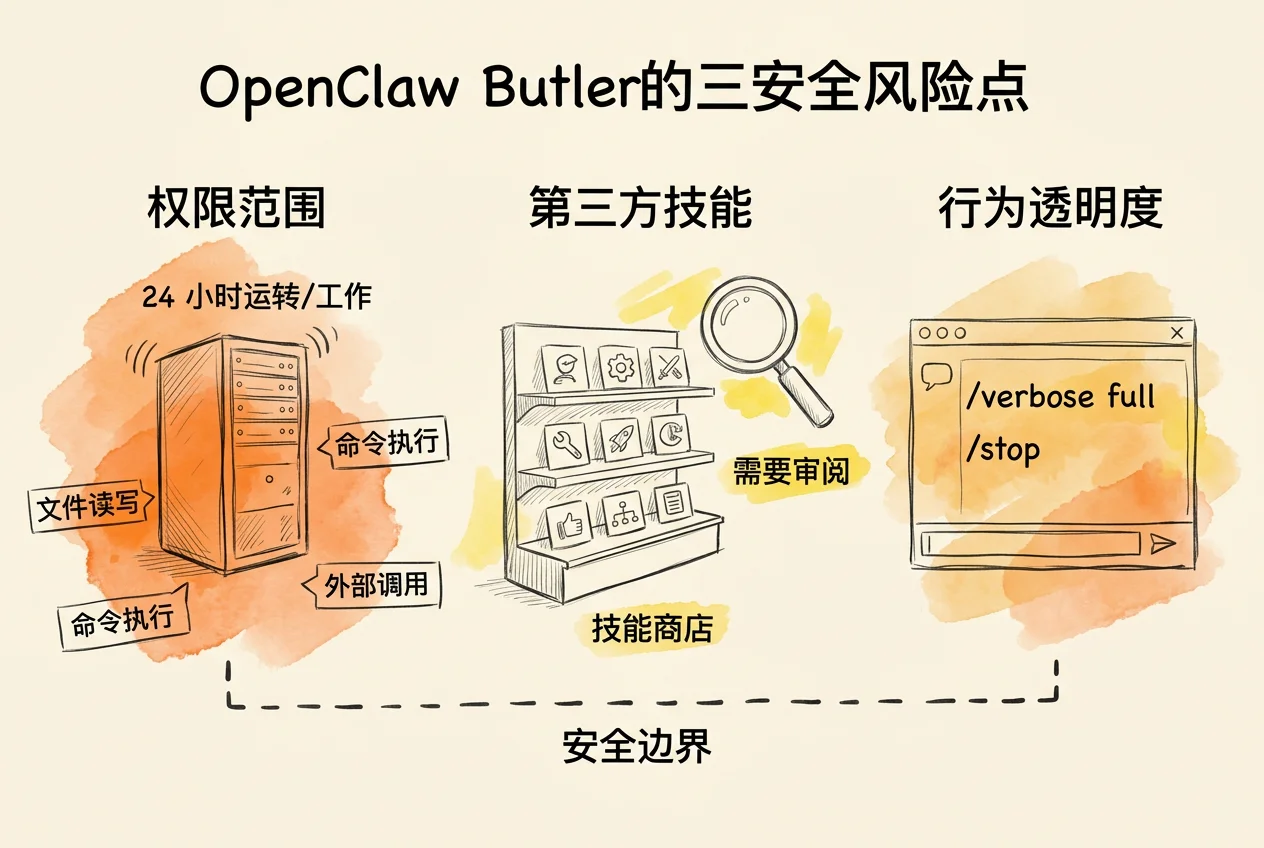
在日常使用之前,有三件事需要留意。
管家的权限比 Opencode 更值得警惕。 Opencode 在你眼前的终端里运行,关掉终端就停了。管家不同:它作为后台进程 24 小时运行在服务器上,能读写文件、执行命令、调用外部服务,而你大部分时间并不在旁边看着。工作区目录只是逻辑上的边界,不是真正的隔离墙。这也是本书推荐首先将 OpenClaw 部署在独立云服务器、而非个人电脑上的原因之一。
第三方技能需要审阅后再安装。 ClawHub 的发布门槛较低,没有代码审计机制。技能安装即生效,如果结合定时任务,还能在你不在线时反复执行。安装前应先阅读技能的说明和权限声明,尤其关注涉及文件读写、网络访问和凭证使用的部分。
管家的后台行为不完全可见。 记忆检索、定时巡查、上下文压缩等过程在后台自动发生,你看不到管家引用了哪些记忆、做了哪些中间判断。在对话中发送 /verbose full 可以让管家把每一步工具调用和输出都作为单独的消息发送出来,相当于打开了操作的实况转播。发现异常时,发送 /stop 可以立即中断当前正在执行的任务。但默认状态下 verbose 是关闭的,管家在后台做了什么、引用了哪些记忆、调用了哪些工具,你并不知道。养成定期开启 /verbose on 观察管家行为的习惯,是建立信任的第一步。