10.4 构建中间知识层:LLM Wiki 模式
面向经管学生、研究者与从业者的 AI 智能体设计教材
结构化索引解决了”让智能体找到文档”的问题,但每次查询时,智能体仍然需要从原始文档中重新阅读和综合信息。如果同一个问题反复出现,系统每次都从零推导,不会变得更快或更准确。
LLM Wiki 模式在索引之上增加了一个关键步骤:让 LLM 预先阅读原始文档,将分散的信息编译为结构化的知识条目。查询时,智能体读取的不再是原始文档,而是已综合整理的知识页面。
从组织文档到编译知识
结构化索引的工作方式是:建立清晰的目录结构和索引文件,智能体通过读取索引定位原始文档,再从原始文档中提取答案。知识的载体始终是原始文档本身。
LLM Wiki 在这个流程中插入了一个”编译”步骤:
| 阶段 | 结构化索引 | LLM Wiki |
|---|---|---|
| 存储 | 原始文档 + 索引文件 | 原始文档 + wiki 知识页面 + 索引 |
| 查询 | 读索引 → 定位文档 → 阅读原文 → 综合回答 | 读索引 → 定位 wiki 页面 → 直接使用 |
| 知识形态 | 分散在各文档中 | 已综合、交叉引用、结构化 |
| 重复查询 | 每次从头推导 | 直接读取已编译的知识 |
2026 年 4 月,Andrej Karpathy 在 GitHub Gist 上发布了 LLM Wiki 的完整设计,引发了社区对知识库设计范式的广泛讨论。
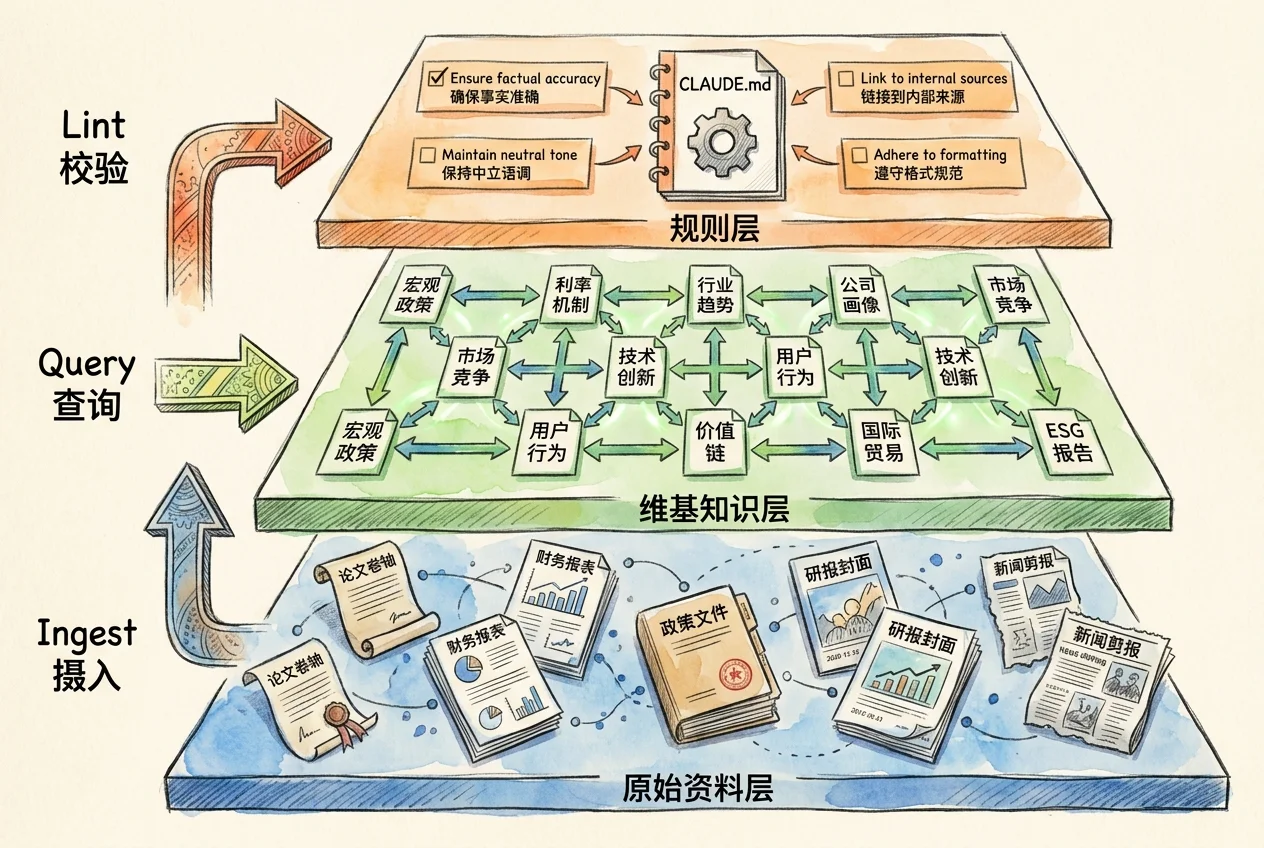
三层架构
LLM Wiki 的核心是三层分离架构,每层有明确的所有权和职责:
my-research/
├── raw/ # 第一层:原始资料层
│ ├── articles/ # 文章、论文、数据文件
│ ├── papers/ # LLM 只读不写
│ └── repos/ # 由人策展和维护
├── wiki/ # 第二层:维基知识层
│ ├── index.md # 总索引(导航入口)
│ ├── log.md # 操作日志
│ ├── concepts/ # 概念条目(如"量化宽松")
│ ├── entities/ # 实体条目(如"美联储")
│ └── sources/ # 来源摘要(每篇原始文档的精炼)
├── outputs/ # 产出物(研究报告、分析备忘等)
└── CLAUDE.md # 第三层:规则层(Schema)- 原始资料层(
raw/):人管理,LLM 只读。这是事实验证的基线,保证知识的可溯源性 - 维基知识层(
wiki/):LLM 生成和维护,人可浏览审阅。每个条目带 YAML 头部,包含标题、类型、来源、日期等结构化元数据 - 规则层(
CLAUDE.md):人和 LLM 共同演进。定义页面结构、命名规范、操作流程和领域特定的约束
这种分层设计确保了原始资料的不可变性——LLM 可以自由地编译和整理知识,但不会修改原始来源。当 wiki 页面的准确性存疑时,随时可以回溯到 raw/ 中的源文档进行验证。
三个核心操作
LLM Wiki 通过三个操作维护知识库的生命周期。每个操作都有明确的输入、执行逻辑和产出物。
Ingest(摄入):向知识库提供新的源文档。LLM 阅读原始文档后,执行以下步骤:
- 撰写来源摘要页(
wiki/sources/下新建文件) - 更新
wiki/index.md索引,添加新页面条目和一句话摘要 - 刷新相关的实体页和概念页——如果页面已存在则补充新信息,不存在则新建
- 在
wiki/log.md记录操作:日期、源文件路径、受影响的 wiki 页面列表
一份 10 页的行业研报通常触发 10-15 个 wiki 页面的创建或更新。
Query(查询):向知识库提问。LLM 先读 wiki/index.md 定位相关页面,钻入内容,综合作答并标注来源。关键机制:当综合答案构成新知识时,系统自动将其写回为一个新的 wiki 页面,后续查询立即受益。
Lint(审校):定期运行健康检查。LLM 扫描知识库,逐项检查:
- 页面间是否存在矛盾观点(如不同研报对同一公司的相反评级)
- 超过 90 天未更新的页面标记为待审查
raw/中是否有文档未被摄入- 无入链的孤立页面是否需要清理
Karpathy 建议每周或每次大批量摄入后执行一次 Lint。
三个操作的成本分布不均衡。Ingest 是最重的操作——一份 10 页 PDF 可能触发 12 个 wiki 文件更新,token 消耗约为源文档的 5-8 倍。Query 和 Lint 相对轻量。建议在项目初期集中完成核心文档的摄入,后续转为增量更新。
LLM Wiki 有一个内在风险:认知漂移(Epistemic Drift)。LLM 生成的 wiki 页面会成为后续查询的知识来源,摄入时的微小错误可能在后续编译中被放大。Lint 操作可以缓解这个问题,但无法完全消除。保持 raw/ 层的不可变性,是防止漂移的最后防线。
知识的复合增长
LLM Wiki 与 RAG 最根本的区别在于知识是否积累。
RAG 是无状态的:每次查询独立运行,检索-增强-生成三步走完即丢弃,不在系统中留下任何沉淀。
LLM Wiki 是有状态的:每次摄入和查询都可能产生新的 wiki 页面。这些页面通过交叉引用(wikilinks)互相连接,形成知识网络。新知识建立在已编译的知识之上,而非每次都从原始文档重新推导。
Karpathy 将这种特性称为复合增长原则(Compounding Principle)。以投研知识库为例:
| 操作 | 知识库变化 |
|---|---|
| 摄入第一份新能源行业报告 | 创建”锂电池”概念页和”宁德时代”实体页 |
| 摄入第二份报告 | 在已有概念页和实体页上叠加新信息,标注与已有观点的一致或矛盾 |
| 查询”宁德时代的竞争格局” | 直接返回已综合多份报告的实体页,而非临时拼接检索片段 |
| 摄入第三份报告 | 自动关联到已有的”锂电池”概念页,补充产能数据和价格趋势 |
十份报告的知识库不是十份报告的简单堆叠,而是一张互相连接的知识网络。Karpathy 本人的 wiki 在约 100 篇文章、40 万字时仍可高效运行。
规模边界与社区扩展
LLM Wiki 的核心逻辑是:不在查询时临时处理原始文档,而是预先编译为结构化 wiki 页面,查询时直接使用编译结果。规模边界取决于 index.md 的大小——wiki 页面数量超过 200-500 篇时,扁平索引文件本身会超出上下文窗口,系统开始退化。
Karpathy 的原始提案激发了多个社区项目,在不同方向上扩展了 LLM Wiki 的能力:
| 项目 | 扩展方向 | 解决的问题 |
|---|---|---|
| LLM Wiki v2(agentmemory 团队) | 知识图谱层 + BM25/向量/图谱三路混合检索 + 置信度评分 | 扁平索引在大规模知识库中的失效 |
| QMD(Shopify CEO Tobi Lutke) | 本地 Markdown 混合搜索引擎 + MCP Server | 支持 Claude Code 直接对接 |
SwarmVault 等社区项目进一步扩展了 LLM Wiki 的能力边界,支持 Schema 引导编译和多格式摄入,将非文本资料纳入知识化流程。
其中 QMD 提供的 MCP Server 模式对投研场景最实用——研究员在 Claude Code 中直接查询本地 wiki,无需额外部署服务。