13.4 系统级评估:判断整套代理机制会不会漂移、回归或失控
面向经管学生、研究者与从业者的 AI 智能体设计教材
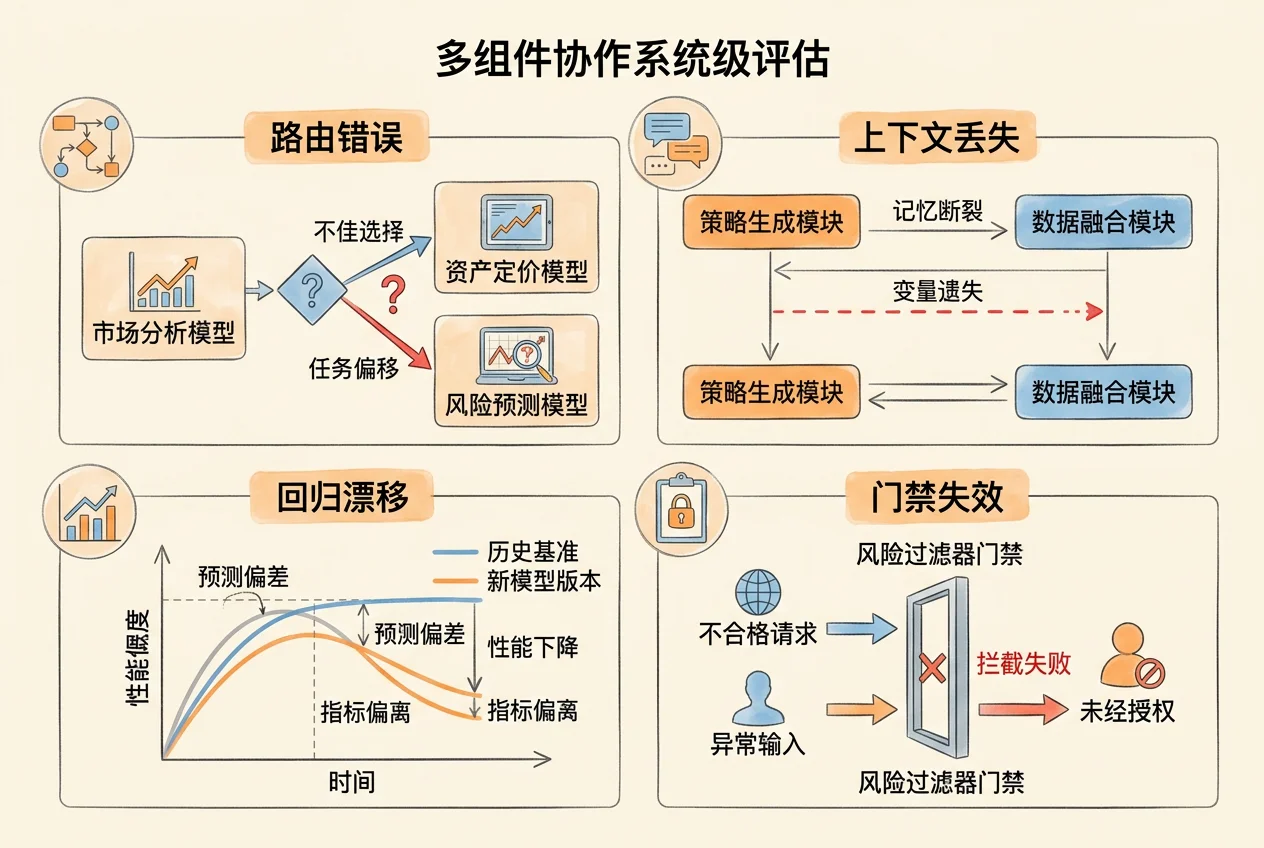
任务级评估检查单次输出,Skill 级评估检查封装稳定性。当多个 Skill、多个代理、多种工具在同一工作流中协作时,还会出现另一类问题:单个组件都正常,组合起来却产出错误结果。
系统级评估关注的不是某次任务或某个 Skill,而是整套代理机制在持续运行中是否会漂移、回归或失控。
系统级评估关注什么
和前两层相比,系统级评估的视角进一步上移:
| 维度 | 任务级 | Skill 级 | 系统级 |
|---|---|---|---|
| 评估对象 | 单次输入-输出 | 同一 Skill 多次执行 | 多组件长期协作 |
| 核心指标 | 输出质量 | 触发准确率、输出稳定性 | 路由正确性、回归率、成本趋势 |
| 典型失败 | 格式错误、事实不准 | 误触发、骨架不一致 | 路由错误、上下文丢失、功能回归 |
| 优先修改 | 任务描述、示例 | description、工具权限 | 代理分工、Hooks、Git 基线 |
系统级评估要回答的核心问题是:修改了一个地方,其他地方是否也出现了问题。
路由与代理协作
当工作流包含多个代理时,第一个系统级检查点是路由,也就是任务是否分配给了正确的代理。
路由错误的常见表现:
- 任务漏分配:某个子任务没有被任何代理接收,导致最终输出缺少一个模块
- 任务重复分配:两个代理同时处理了同一个子任务,产出冲突的结果
- 能力错配:需要数据分析的任务被分配给了文本写作代理
检查路由稳定性的方法很简单:用同一组输入重复运行 3-5 次,观察任务分配结果是否一致。如果相同输入在不同运行中被分配给不同代理,说明路由规则还不够明确。
上下文传递是另一个高频问题。多代理协作时,前一个代理的输出会成为后一个代理的输入。如果中间环节丢失关键信息,后续代理就会基于不完整的上下文做出错误判断。
检查上下文传递的方法:
- 在每个代理的输出中标注关键信息(如数据来源、计算结果、约束条件)
- 在下一个代理的输入中验证这些关键信息是否完整传入
- 记录每次传递中丢失的信息类型和频率
Hooks 作为质量门禁
Hooks 在系统级评估中承担自动校验角色。它挂在关键节点上,可以在代码提交前、文件写入后、工具调用时自动检查输出是否满足预设条件。
系统级评估需要检查 Hooks 本身的有效性:
| 检查项 | 说明 | 失败信号 |
|---|---|---|
| 覆盖率 | 关键节点是否都挂了 Hook | 某些错误输出没有被拦截 |
| 误拦截 | 正常输出是否被错误拦截 | 合格的提交被频繁阻止 |
| 漏拦截 | 不合格输出是否逃过了检查 | 错误内容进入了下游环节 |
| 性能影响 | Hook 执行是否拖慢了工作流 | 提交或执行延迟明显增加 |
如果 Hook 的误拦截率过高,团队就会倾向于跳过检查(--no-verify),反而削弱系统安全性。Hook 规则需要精准,不能一味放宽或泛化。
回归与漂移
回归是指修改系统某个部分后,原本正常的功能变得不正常。这在多组件系统中尤其常见。比如改了一个 Skill 的输出格式,依赖该输出的另一个代理就可能解析失败。
回归检测的基本方法:
- 建立基线:选定一组输入,记录当前版本的输出作为基线
- 每次修改后对比:用同一组输入重新运行,将新输出与基线对比
- 标记差异:区分”预期内的变化”和”意外的退化”
def check_regression(baseline: dict, current: dict) -> list:
"""对比基线和当前输出,返回退化项"""
regressions = []
for test_id, expected in baseline.items():
actual = current.get(test_id)
if actual is None:
regressions.append(f"{test_id}: 输出缺失")
elif not meets_criteria(actual, expected):
regressions.append(f"{test_id}: 质量下降")
return regressions漂移比回归更隐蔽。它不是某次修改导致的突变,而是系统在持续运行中逐渐偏离预期行为。常见类型包括:
- 输出风格漂移:报告的语言风格、用词习惯在多轮迭代后逐渐变化
- 长度漂移:输出长度在连续多次运行后越来越长或越来越短
- 结构漂移:输出的章节结构在多轮修改后偏离了最初的模板
检测漂移需要定期抽样,而不能只在修改后检查。可以每隔固定次数,如每 10 次执行,做一次全量对比。
成本与延迟监控
系统级评估还要关注运行成本和响应速度。功能正确但消耗过高的系统,在实际使用中同样不可接受。
需要监控的指标:
| 指标 | 关注点 | 警戒线示例 |
|---|---|---|
| 单次任务 token 消耗 | 是否有提示词膨胀 | 同类任务 token 增长超 50% |
| 工具调用次数 | 是否有冗余调用 | 同一工具被连续调用 3 次以上 |
| 端到端延迟 | 是否有环节阻塞 | 响应时间超出基线 2 倍 |
| 失败重试次数 | 是否有循环重试 | 同一步骤重试超过 3 次 |
成本异常往往是系统问题的早期信号。比如 token 消耗突然增加,往往说明上下文传递出了问题,代理在重复生成已有信息。
系统级失败的归因
系统级问题往往表现为最终输出不对,但真正的原因分散在多个环节。归因时可以按以下顺序排查:
| 优先级 | 检查项 | 典型症状 | 修改动作 |
|---|---|---|---|
| 1 | 代理分工与路由 | 任务分配错误或遗漏 | 明确路由规则、调整代理职责 |
| 2 | 上下文切分与传递 | 后续代理缺少关键信息 | 规范交接文件格式、增加必传字段 |
| 3 | Hooks 门禁 | 错误输出未被拦截 | 补充检查规则、调整拦截阈值 |
| 4 | Git 版本与基线 | 无法确认何时引入问题 | 建立版本对比机制、缩小提交粒度 |
| 5 | 经验写回 | 同类错误反复出现 | 把解决方案写入 CLAUDE.md 或 Skill |
系统级评估里有一个关键判断:很多被归结为模型能力不够的问题,实际属于系统协作问题。模型单独测试时表现正常,但放进多代理工作流后出错,原因通常在路由、上下文传递或 Hook 配置,而不是模型本身。
本节一句话总结: 系统级评估看的是路由、上下文、Hooks、回归和成本,解决的是”整套机制会不会越改越乱”。