21.2 从项目隔离到常驻:为什么需要管家
面向经管学生、研究者与从业者的 AI 智能体设计教材
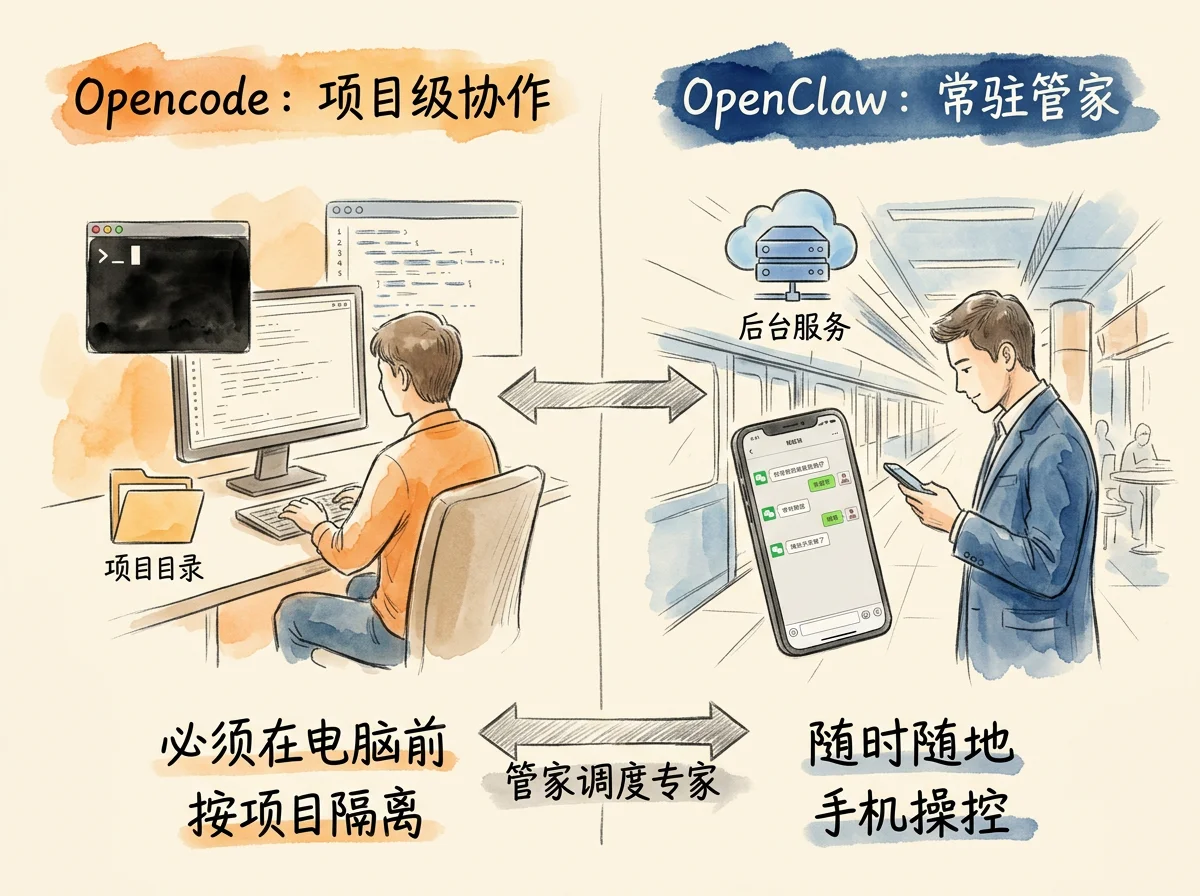
Opencode 在自己的项目目录里已经能完成相当复杂的工作,比如写一份研报、整理一批文献、跑一遍数据分析。但它有一个基本前提:必须打开电脑、进入对应的项目目录才能调用。当需求从”我要做这个项目”变成”AI 应该一直在、随时能对它说话”,按项目隔离的协作工具就触及上限。
两个形态上的限制
按项目隔离的设计是 Opencode 适合深度工作的关键,但这种”以项目为中心、需要在场操作”的形态,也带来了两个限制。
必须在该项目目录里打开 Opencode 才能用。 要做哪个项目,就要先进入那个项目目录。想同时推进多个项目,就在每个项目目录各开一个终端。
远程接入能力有限。 即便有远程控制功能,也需要事先在那台机器上把工具跑起来。临时想起一个没有提前准备好的项目,手机上调不动它。
常驻模式带来的改变
OpenClaw 启动后会作为一个后台守护进程持续运行,不会因单轮对话结束而退出。这带来三项能力差异。
/new
OpenClaw 常驻后台运行,你通过微信等渠道发消息即可与它交互。跟它的每一段连续对话都是一个会话。会话内的上下文连续累积;如果想换个话题、不希望前面的内容继续影响管家的判断,发一句 /new 就开启一个新会话,旧上下文清空,和在 Opencode 里用 /clear 是同一种感觉。
| Opencode 的限制 | OpenClaw 的应对 |
|---|---|
| 必须在该项目目录里打开 Opencode 才能用 | 部署到一台始终开机的机器上后,从手机微信等渠道随时调度 |
| 远程接入能力有限,需要事先准备 | 部署一次后任意时刻发消息都接得上,不需要事先做任何准备 |
常驻意味着外出、睡眠、开会时,管家依然可以接收消息、完成任务、发出通知。多渠道接入把交互入口从”必须在某台电脑的某个目录里”扩展到”手机上随时打开的消息软件”。这些软件本身持续运行,且始终在身边。
管家与专家:分工协作
常驻模式解决了”人不在场也能调度 AI”的问题,但 OpenClaw 并非 Opencode 的替代品。两者擅长的领域不同,强行让一个系统同时承担常驻调度和深度工作,两边都难以做好。
管家(OpenClaw)的职责。 在所连接的渠道(如微信)里接收指令,理解请求意图,调度合适的执行方式:能直接答的就自己答,需要进项目目录深度处理的转交给 Opencode,最后把结果按原路推回。简单的文件读取、搜索查询、信息整理,管家自己就能完成。
专家(Opencode)的职责。 进入某个具体项目目录,加载该项目的上下文,执行深度的写作、分析、推理。需要完整的项目语境,由管家通过 opencode run 命令调用,完成后退出。
常见的组合用法是:通过手机给管家发一句消息,管家根据任务复杂度决定处理方式。简单的自己直接答;需要项目语境的,自动转交 Opencode 进入对应项目目录执行,完成后把结果回送回来。
三个典型场景
场景一:通勤路上触发研报更新(我 → 管家 → Opencode → 管家 → 我)。 地铁上想起一份银行业周报需要刷一下,打开微信给管家发:
帮我用 ~/research/银行业周报 这个项目里的模板,把本周的新闻和数据更新进去管家收到指令,识别到这是项目级深度任务,自动通过 opencode run 进入服务器上的 ~/research/银行业周报 目录调起 Opencode;Opencode 加载该项目的规则文件、历史章节、数据脚本,拉取本周数据、续写新一节内容;完成后退出。管家拿到结果,把摘要和新版周报文件发回微信。整个过程人没有打开自己手边的电脑,只是在手机上发了一条消息、收到一条回复。
场景二:凌晨自动巡查 + 异常时调专家撰写简报(管家 → Opencode → 管家 → 我)。 给管家配一个定时任务:每天凌晨 4 点扫描指定的几个行业数据源,发现指标偏离阈值时,调起 ~/research/行业监测 项目里的 Opencode 写一份带上下文对比的预警简报,第二天清晨把简报推送到微信。早晨醒来打开手机,已经能看到一份背景分析齐全的预警,而不是只有一条”出现异常”的告警。
场景三:会议间隙快速查个事(我 → 管家 → 我)。 开会时想确认一件事:上周和某客户聊过的需求记到哪去了。给管家发:
查一下我 ~/notes/客户A 目录里上周记录的需求要点这件事不需要项目级深度处理,管家直接读取该目录里的 markdown 文件,把要点列出来回到微信里。整个过程不调用 Opencode,管家自己完成。
管家的价值在于判断什么自己做、什么转交、什么时候触发。