8.3 任务分派与输入输出设计
面向经管学生、研究者与从业者的 AI 智能体设计教材
任务要说清楚,信息要传对,输出要约定好。
调用子代理的三种方式
Claude Code 提供三种不同粒度的子代理调用方式:
| 调用方式 | 语法 | 行为 | 适用场景 |
|---|---|---|---|
| 自然语言 | 在提示中提及子代理名称 | Claude 自行判断是否委派 | 日常使用,让 Claude 灵活决策 |
| @ mention | @"agent-name (agent)" |
保证该子代理运行 | 需要明确指定子代理时 |
--agent 会话级 |
claude --agent agent-name |
整个会话替换为该子代理的配置 | 将某个专属子代理作为主会话运行 |
自然语言调用是最常见的方式。在提示词中提到子代理的名称或描述其职责,Claude 会根据已有子代理的 description 字段判断是否委派:
用 financial-analyst 子代理分析贵州茅台的盈利能力@ mention 提供了更强的控制力。输入 @ 后从 typeahead 列表中选择子代理,可以确保指定的子代理一定会被调用:
@"financial-analyst (agent)" 分析贵州茅台 2024 年三项盈利能力指标如果子代理名称不含空格,可以直接手动输入 @financial-analyst;含空格时必须用引号包裹。
--agent 会话级运行将整个 Claude Code 会话替换为该子代理的系统提示词、工具限制和模型配置。适合把某个专属子代理作为独立工作台使用。
子代理每次调用都会创建新实例。如果需要继续已完成的子代理的工作,Claude 可以通过 SendMessage 工具向已完成的子代理发送新消息,子代理自动在后台恢复运行,保留之前所有的工具调用记录和推理过程。
任务提示词的写作要领
子代理收到的提示词会直接影响执行质量。一个好的任务提示词包含四个要素:
| 要素 | 说明 | 示例 |
|---|---|---|
| 明确目标 | 子代理需要完成什么 | 计算贵州茅台 2024 年三项盈利能力指标 |
| 提供上下文 | 完成任务需要知道什么 | 年报数据文件路径为 data/maotai-2024.csv |
| 约定输出格式 | 结果应该是什么样子 | 输出为 Markdown 表格,包含指标名称、数值和同比变化 |
| 设定约束 | 边界条件和注意事项 | 数值保留两位小数,异常波动需标注 |
一个完整的任务提示词示例:
请创建 1 个财务分析子代理,专门分析贵州茅台 2024 年度财务报表的盈利能力。
主代理职责:
- 只负责发起子代理和接收状态摘要
- 不自己展开财务指标计算
输入数据:data/maotai-2024.csv
参考说明:data/financial-metrics-guide.md 中有指标定义
子代理任务:
1. 计算毛利率、净利率、ROE 三项指标
2. 与 2023 年数据对比,计算同比变化
3. 对异常波动(变化超过 20%)给出可能原因
输出要求:
- 将完整分析报告保存到 output/maotai-profitability.md
- 报告包含数据表格和文字分析
- 数值保留两位小数
- 完成后只返回一句话摘要说明结果好的委派应把五个要素写清楚:清晰目标、输出格式、工具建议、来源范围和任务边界。对比两种写法:❌ 分析一下新能源行业;✅ 从 Wind 数据库提取 2024 年国内前五大新能源车企的季度营收数据,计算同比增长率,结果保存为 JSON 到 temp/ev-revenue.json。精确度越高,执行质量越稳定。
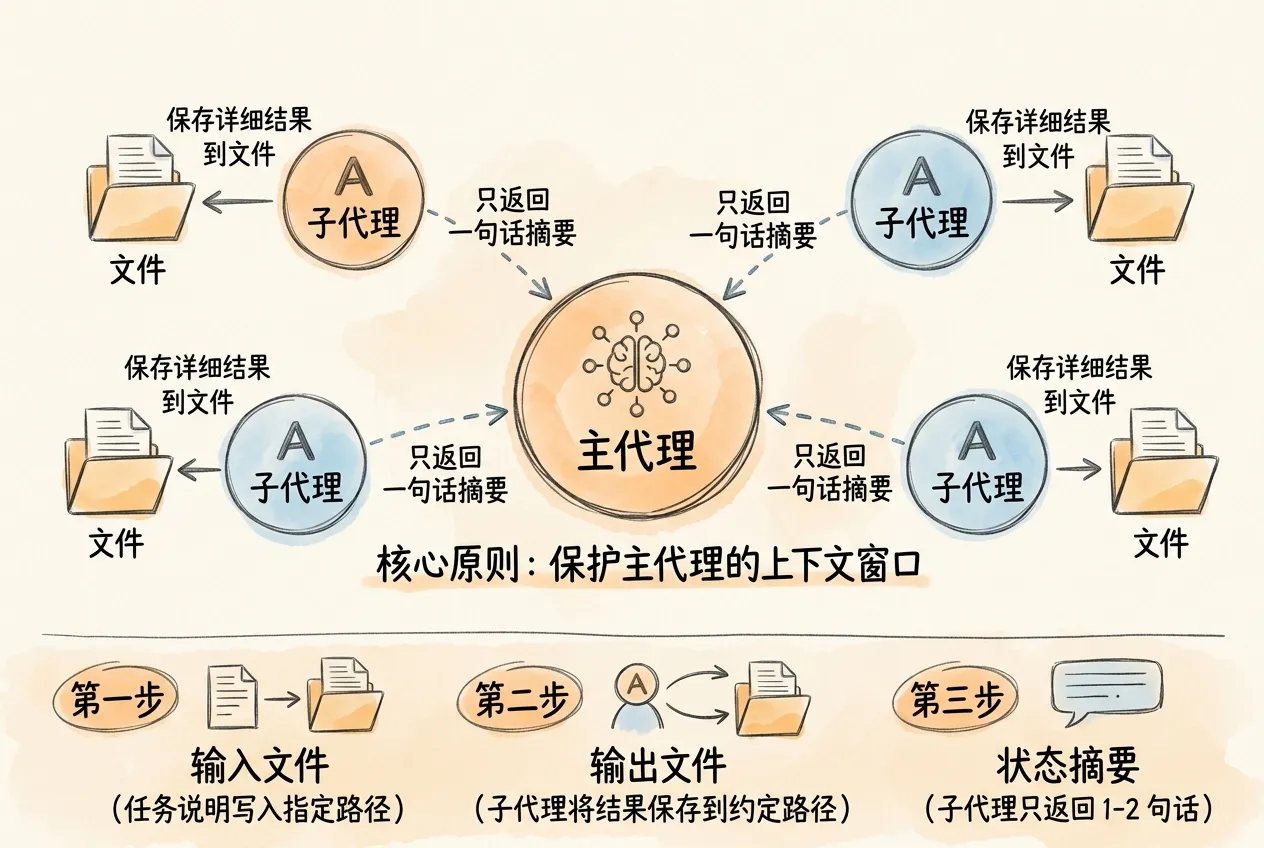
文件化信息传递策略
File Handoff 是使用子代理时最重要的实践原则。 核心思想:子代理将结果保存到文件,只返回简短摘要。
子代理返回的内容都会进入主代理的上下文窗口。如果三个子代理各自返回一份 3000 字的分析报告,主代理就要额外承载 9000 字内容,这部分空间本应用于决策和整合。
主代理的上下文窗口最稀缺。 子代理应把详细结果保存到文件中,只向主代理返回状态摘要,例如:分析完成,报告已保存到 output/maotai-profitability.md,ROE 为 25.3%,同比下降 2.1 个百分点。
文件化传递分三个环节:
- 输入文件:将任务说明和参考资料写入指定路径,让子代理自行读取,而不是把大段文本写入 prompt
- 输出文件:要求子代理将结果保存到约定路径(如
output/maotai-profitability.md) - 状态摘要:子代理完成后只返回
1-2句话的摘要
主动管理信息去向,是上下文工程(Context Engineering)的核心做法。每次决定一条信息该放进 prompt 还是写入文件,本质上都在做上下文工程的决策。
智能体不擅长判断一项任务该花多大力气。Anthropic 的做法是直接在提示词里规定投入规模:
| 任务类型 | 子代理数量 | 金融场景举例 |
|---|---|---|
| 简单事实查询 | 不需要子代理 | 查询某只股票的最新收盘价 |
| 对比分析 | 2-4 个 | 对比三家公司的盈利能力指标 |
| 深度研究 | 5 个以上 | 行业深度报告、跨市场投资策略 |
输入输出的标准化设计
当多个子代理协作时,标准化的输入输出格式可以减少出错和返工。
JSON 结构化数据适合传递数值型结果:
{
"company": "贵州茅台",
"period": "2024年度",
"metrics": {
"profitability": {
"gross_margin": 0.915,
"net_margin": 0.482,
"roe": 0.253
}
},
"anomalies": [
{ "metric": "roe", "change": -0.021, "note": "受投资收益下降影响" }
]
}Markdown 文档适合人类直接阅读的报告。先约定统一的文档结构,可以让不同子代理生成的报告保持一致:
# [公司名] [年度] 财务分析报告
## 概要
[2-3 句话的核心结论]
## 数据表
| 指标 | 当期值 | 上期值 | 同比变化 |
|------|-------|-------|---------|
## 分析
[文字分析]建议采用 {任务类型}/{公司代码}-{分析维度}-{日期}.{格式} 的命名方式,例如 output/600519-profitability-20240331.md。统一的命名规则让主代理和后续流程能自动定位结果文件。