10.2 基于嵌入的检索增强生成
面向经管学生、研究者与从业者的 AI 智能体设计教材
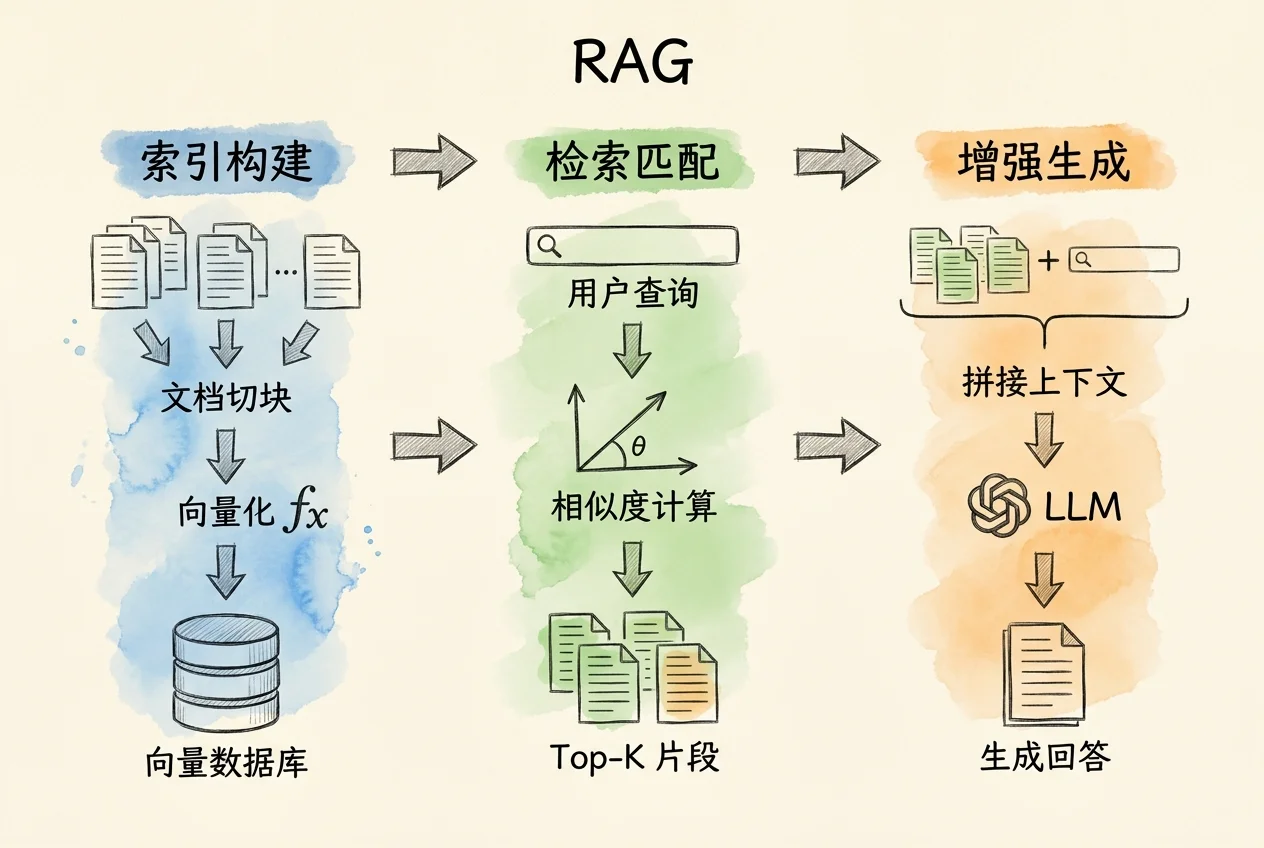
检索增强生成(Retrieval-Augmented Generation, RAG)是当前应用最广的知识库方案。核心思路是:用户提问时,先从外部文档库中检索相关片段,再把这些片段作为上下文交给模型生成回答。模型不再仅凭参数记忆作答,而是基于实时检索到的证据。
RAG 核心流程
RAG 管道分三个阶段:
- 检索(Retrieval)。将用户查询和文档库内容分别转换为向量表示,通过语义相似度匹配找出最相关的文档片段。这一步决定了系统上限——检索不到正确信息,后续生成再好也无法弥补。
- 增强(Augmentation)。将检索到的文档片段与用户问题组装成结构化提示词,典型模板包含系统指令、检索结果和用户原始问题三部分。
- 生成(Generation)。模型基于增强后的提示词生成回答。此时模型有外部证据支撑,可以引用具体来源,减少幻觉。
RAG 流程示意:
用户提问 ──→ 查询向量化 ──→ 向量数据库检索 Top-K
│
检索结果 + 原始问题
│
↓
组装增强提示词 ──→ 模型生成回答嵌入向量(Embedding)是一段文本的数学表示。嵌入模型(Embedding Model)将文本映射到高维空间中的一个点,语义相近的文本在空间中距离更近。RAG 系统利用这一性质,通过计算向量距离来判断文档片段与查询的相关程度。
关键技术选择
搭建 RAG 系统需要做的技术决策主要集中在分块策略、向量化模型和向量数据库三方面。下面逐一展开。
分块策略
文档入库前需要切分为较小的片段(chunk)。分块质量直接影响检索精度。
| 策略 | 原理 | 适用场景 |
|---|---|---|
| 固定长度 | 按字符或 token 数硬切 | 仅适合原型验证 |
| 递归分割 | 按段落、句子、字符逐层切分 | 大多数文本的推荐起点 |
| 语义分段 | 对相邻句子做嵌入,相似度低于阈值时切开 | 知识库、技术文档 |
| 自适应分段 | 由 LLM 判断语义边界 | 复杂多文档场景 |
递归分割配合 256-512 token 块大小、10%-20% 重叠率是经验上的稳健起点。
金融文档有明确的章节和表格结构——财报的”管理层讨论与分析”和”财务报表附注”、研报的”投资建议”和”风险提示”——适合在递归分割基础上添加元数据标注(公司名、报告期、板块),提升检索时的过滤能力。
向量化模型
向量化模型决定文本的语义表示质量。选型时关注四个维度:检索基准排名、向量维度、最大 token 数、中文支持。
| 模型 | 维度 | 中文支持 | 适用场景 |
|---|---|---|---|
| OpenAI text-embedding-3-large | 3072 | 良好 | 通用场景,API 调用便捷 |
| BGE-M3 | 1024 | 优秀 | 中文金融文档,可本地部署 |
| Cohere Embed v3 | 1024 | 良好 | 多语言混合文档 |
| Voyage Finance-2 | 1024 | 一般 | 英文金融术语密集场景 |
更换嵌入模型意味着全量重新索引。系统设计时要为模型升级留出空间,避免与某个特定模型强绑定。
向量数据库
| 使用场景 | 推荐方案 | 理由 |
|---|---|---|
| 快速原型 / 教学 | Chroma | 嵌入式运行,几行代码启动 |
| 零运维托管 | Pinecone | 全托管服务,免费支持 100K 向量 |
| 混合检索 | Weaviate | 原生支持向量 + 关键词混合搜索 |
| 超大规模 | Milvus | GPU 加速,支持十亿级向量 |
知识图谱增强
传统 RAG 以文本片段为检索单位,片段之间相互独立。当回答需要跨文档综合信息时——“比较 A 公司和 B 公司过去三年的研发投入趋势”——系统只能拼凑来自不同文档的碎片,难以产生连贯的综合分析。
知识图谱增强检索(GraphRAG)在向量检索之上增加了关系推理层:
- 从原始文档中抽取实体(公司、人物、指标)和关系(投资、合作、竞争)
- 将实体和关系组织为图结构
- 检索时同时利用向量相似度和图遍历,找到语义相关且逻辑关联的信息
| 维度 | 传统 RAG | GraphRAG |
|---|---|---|
| 检索单位 | 文本片段 | 实体、关系、社区摘要 |
| 跨文档能力 | 弱,各片段独立 | 强,实体天然跨文档连接 |
| 多跳推理 | 不支持 | 通过图遍历实现 |
| 索引成本 | 低 | 高(约为基线 RAG 的 3-5 倍) |
GraphRAG 的优势随查询复杂度增长而放大。简单的事实查找不需要图谱增强;需要跨文档关联、多跳推理的复杂分析才能体现其价值。金融分析中常见的产业链上下游关系、股权穿透、关联交易追溯,都属于多跳推理场景。
LightRAG 是 GraphRAG 的轻量替代方案,去掉了重型社区检测环节,支持增量更新,查询延迟更低。两者互补:GraphRAG 适合离线深度分析,LightRAG 适合在线实时场景。
RAG 在金融场景的典型痛点
RAG 是成熟且实用的方案,但在金融场景中有四个结构性局限:
每次查询从零开始,无知识积累。 RAG 管道是无状态的:用户提问、检索、生成、丢弃上下文。系统不会记住上一次查询发现了什么。分析师连续三天研究同一家公司的财报,每次提问系统都重新检索,无法建立递增的分析视角。
跨文档综合能力弱。 检索以片段为单位,返回的是来自不同文档的独立碎片。券商分析师需要综合五份研报得出行业评级时,系统只能拼凑碎片,无法形成连贯叙事。微软将此称为”连点”(connect the dots)问题。
分块导致信息断裂。 无论用什么分块策略,切分本身就会破坏文档内在逻辑。研报中”投资建议”和”风险提示”往往跨段落,分块后检索可能只命中其中一半,关键条件丢失。
语义相似不等于语义相关。 查询”2024 年 LPR 调整的影响”,向量检索可能返回”2023 年 LPR 调整的影响”——语义高度相似但年份错误。金融文档对年份、公司代码、指标名称的精确匹配要求高,纯向量检索无法执行这类结构化过滤。
RAG 不是万能方案。许多团队在知识库建设中默认选择 RAG,却没有评估是否真的需要向量检索。对于文档数量有限、结构清晰的项目,更轻量的方案可能效果更好、维护成本更低。
智能体视角的自适应检索
传统 RAG 是固定管道:每次查询都执行相同的检索流程,无论问题复杂还是简单。智能体化 RAG(Agentic RAG)将检索变成智能体的一个工具——智能体根据问题特征决定是否需要检索、用什么策略、结果是否充分。
三种典型的自适应策略:
- Self-RAG:模型在生成过程中自主判断是否需要检索。遇到自己不确定的事实时触发检索,检索后还会评估结果质量、过滤无关内容。对于金融领域需要精确数据的场景(如具体财务指标),这种按需检索可以同时控制幻觉和降低不必要的检索开销。
- CRAG(纠错式检索增强):增加一个检索评估器,对检索结果按”正确/错误/模糊”三级打分,分数低于阈值时自动补充外部搜索。监管合规查询中,内部政策文档可能未及时更新,CRAG 会自动补充外部来源(如监管机构官网)的最新信息。
- Adaptive RAG:用分类器判断查询复杂度——简单查询跳过检索直接回答,中等查询做单跳检索,复杂查询启动多跳检索。避免”所有问题都做全流程检索”的资源浪费。