10.3 基于文档索引的推理检索
面向经管学生、研究者与从业者的 AI 智能体设计教材
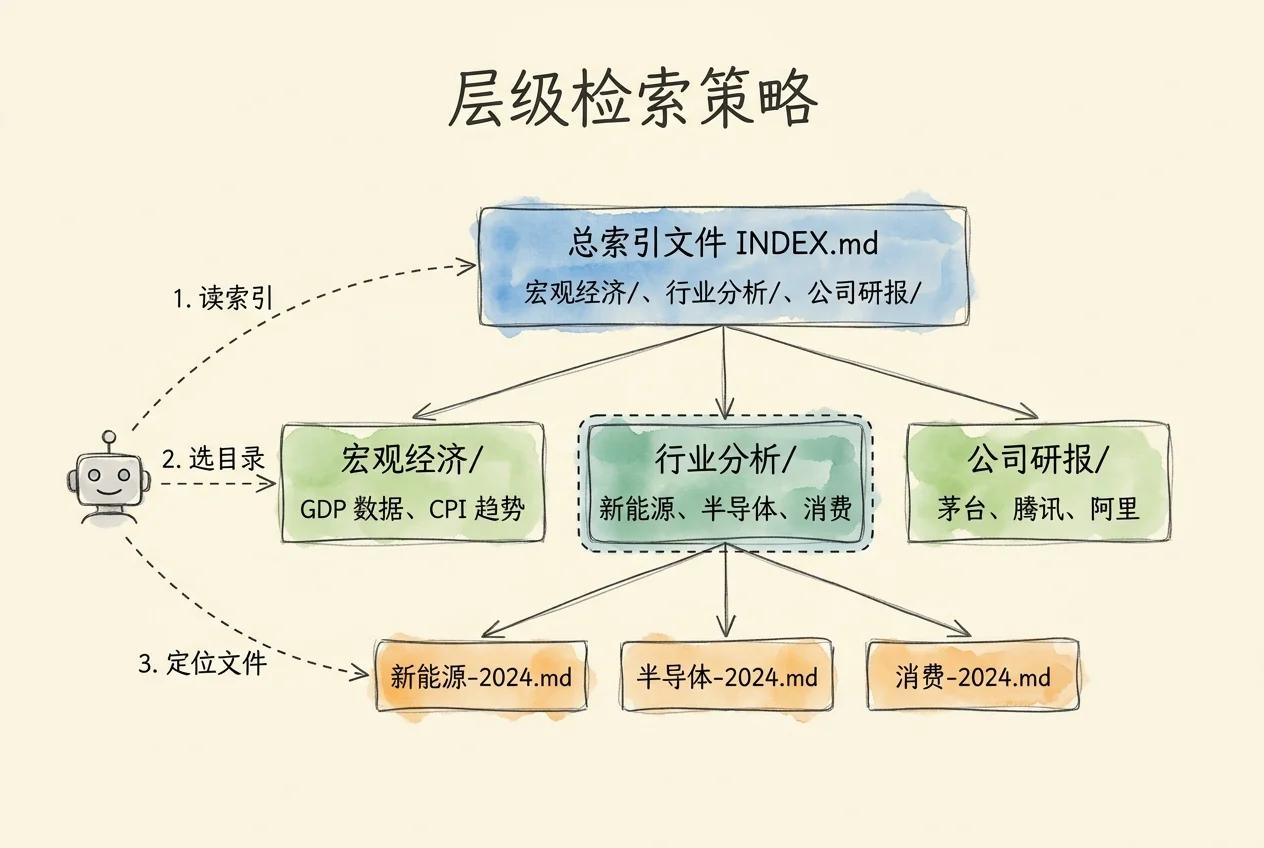
向量嵌入并非唯一的检索手段。另一条路径是:用结构化的目录和索引文件,引导智能体逐层定位信息。这种方法将检索从模式匹配问题重新定义为推理问题——智能体不比较向量距离,而是阅读、判断、深入,直到找到目标内容。
核心思路:让智能体读目录
向量检索的逻辑是:把文档切成碎片,转为数字向量,在高维空间中寻找距离最近的碎片。这个过程快速但不透明,且语义相似不等于内容相关。
推理检索(Reasoning-based Retrieval)走另一条路:
- 智能体读取顶层索引文件,了解知识库整体结构
- 根据问题判断哪个分支最可能包含答案
- 进入子目录,读取更细粒度的摘要或标题
- 到达具体文档,提取正文用于回答
向量检索问的是”哪段文字和查询最像”。推理检索问的是”根据知识库的组织方式,答案最可能在哪里”。前者依赖嵌入模型的表征质量,后者依赖 LLM 的推理能力和索引文件的设计质量。
这条路径在 2025-2026 年变得可行,关键推动力是上下文窗口的扩展。当单次上下文达到 100K token 量级时,智能体可以在单次交互中加载索引文件和多个完整文档,无需预先切块和嵌入。
索引文件的设计
索引文件是这种方法的核心产物。一个设计良好的索引文件包含文档路径、内容摘要和分类信息,让智能体快速判断每个文件的用途。
以下是一个投研知识库的索引文件示例:
# 投研知识库索引
## 最后更新:2026-04-15
## 宏观经济
- macro/pbc-q1-2026.md | 央行 2026 年一季度货币政策执行报告,含 M2 增速、社融数据
- macro/nbs-gdp-2025.md | 国家统计局 2025 年 GDP 核算报告,含分产业增加值
- macro/fed-minutes-mar.md | 美联储 2026 年 3 月议息会议纪要,关注利率路径表述
## 行业研究
- industry/new-energy/ | 新能源行业研究(含 12 份报告),子索引见该目录 index.md
- industry/semiconductor/ | 半导体行业研究(含 8 份报告),子索引见该目录 index.md
- industry/banking/ | 银行业研究(含 15 份报告),子索引见该目录 index.md
## 个股研究
- stock/600519-kweichow.md | 贵州茅台深度报告,含估值模型和产能分析
- stock/300750-catl.md | 宁德时代跟踪报告,含装机量数据和竞争格局索引文件的设计遵循四个原则:
- 摘要要具体:每条摘要写清楚文件包含哪些具体信息。“含 M2 增速、社融数据”比”宏观经济数据”有用得多
- 层级不宜过深:2-3 层为宜,过深的目录树增加智能体的导航成本
- 文件名即元数据:使用有意义的命名(如
pbc-q1-2026.md),让文件名本身传达内容主题 - 保持索引更新:索引与实际文件不同步时,智能体会被引向错误方向
索引文件的总长度建议控制在 200 行以内。超过这个规模,索引本身占据的上下文空间开始影响智能体对指令的遵循度。大型知识库可以采用分层索引:顶层索引只列出子目录和一句话摘要,每个子目录维护自己的详细索引。
Claude Code 的分层加载机制
Claude Code 的多层规则文件天然具备分层加载特性,体现了推理检索的核心思路:
| 组件 | 加载时机 | 加载粒度 |
|---|---|---|
CLAUDE.md |
项目启动时全量读取 | 全文 |
.claude/rules/ |
按路径匹配条件加载 | 匹配的规则文件 |
.claude/skills/ |
搜索阶段只读 YAML 头部(约 100 token),匹配后加载完整内容 | 渐进式 |
子目录 CLAUDE.md |
访问该目录时触发 | 按需 |
智能体根据当前任务上下文决定加载哪些规则文件,而非一次性读入全部内容。这种按需加载依赖的是推理判断,而非向量匹配。
代表性项目:PageIndex
PageIndex 是推理检索领域的代表性开源项目(GitHub 23K+ star,MIT 许可证,VectifyAI 于 2025 年发布)。它将推理检索系统化为两个阶段:
索引阶段:将文档转化为层级 JSON 树。系统检测文档是否有目录结构,若有则提取并验证;若无,则由 LLM 推断章节标题。最终生成递归树,每个节点包含标题、页面范围和内容摘要。
检索阶段:LLM 在树结构上推理导航。系统提供三个工具函数——get_document_structure() 返回不含正文的树结构,get_page_content() 按页码返回正文,get_document() 返回元数据。智能体先读树结构,判断目标分支,逐层钻入,最终提取具体页面内容。
PageIndex 在 FinanceBench 基准测试(专门测试复杂金融报告分析能力)上达到 98.7% 准确率,显著优于传统向量 RAG。它支持 CLI、Python 包、REST API、MCP Server 等多种部署模式,其中 MCP 模式可直接对接 Claude Code。
FinanceBench 是面向金融文档分析的标准化基准测试,包含 150 个来自真实 SEC 年报的问题,覆盖事实查找、数值计算和跨文档推理三类任务。它是评估金融场景 RAG 系统准确率的常用基准。PageIndex 98.7% 准确率数据来源于 VectifyAI 官方 README(2025 年 9 月)。
适用场景与规模边界
推理检索的优势集中在透明性和轻量性两个方面:
- 透明可控:每个检索步骤都有对应的索引节点或文件路径,出错时可以直接检查推理过程
- 零基础设施:不需要向量数据库、嵌入模型和索引管道,纯文件系统即可运行
- 版本友好:索引文件和知识库都是纯文本,天然适配 Git 版本控制
- 领域适应强:不依赖通用嵌入模型,对金融、法律等专业术语不存在嵌入质量问题
规模边界同样清晰。当知识库内容超过模型上下文窗口容量时,这种方法开始失效。当前实际上限约 100K-500K token,取决于具体模型。对于数万份非结构化文档的大规模语料库,向量检索仍然是更合适的选择。
llms.txt 是一项新兴的开放提案:网站在根目录放置一个 LLM 优化的 Markdown 导航文件,供智能体直接读取,替代传统的网页爬取和嵌入流程。这与推理检索的思路一致——用结构化文本索引引导智能体定位信息。
推理检索最适合这类场景:文档结构清晰、规模可控(20-500 份文档)、需要高准确率和可解释性、查询频率高但知识库更新不频繁。投研团队的行业研究报告库、法规合规文件库、项目技术文档库都是典型的适用场景。
但这种方法有一个根本局限:无论索引设计得多好,每次查询时智能体仍然需要阅读原始文档来综合答案。知识始终停留在原始文件中,不会因为反复查询而沉淀为更高效的形态。