10.5 三种方法的对比与常见误区
面向经管学生、研究者与从业者的 AI 智能体设计教材
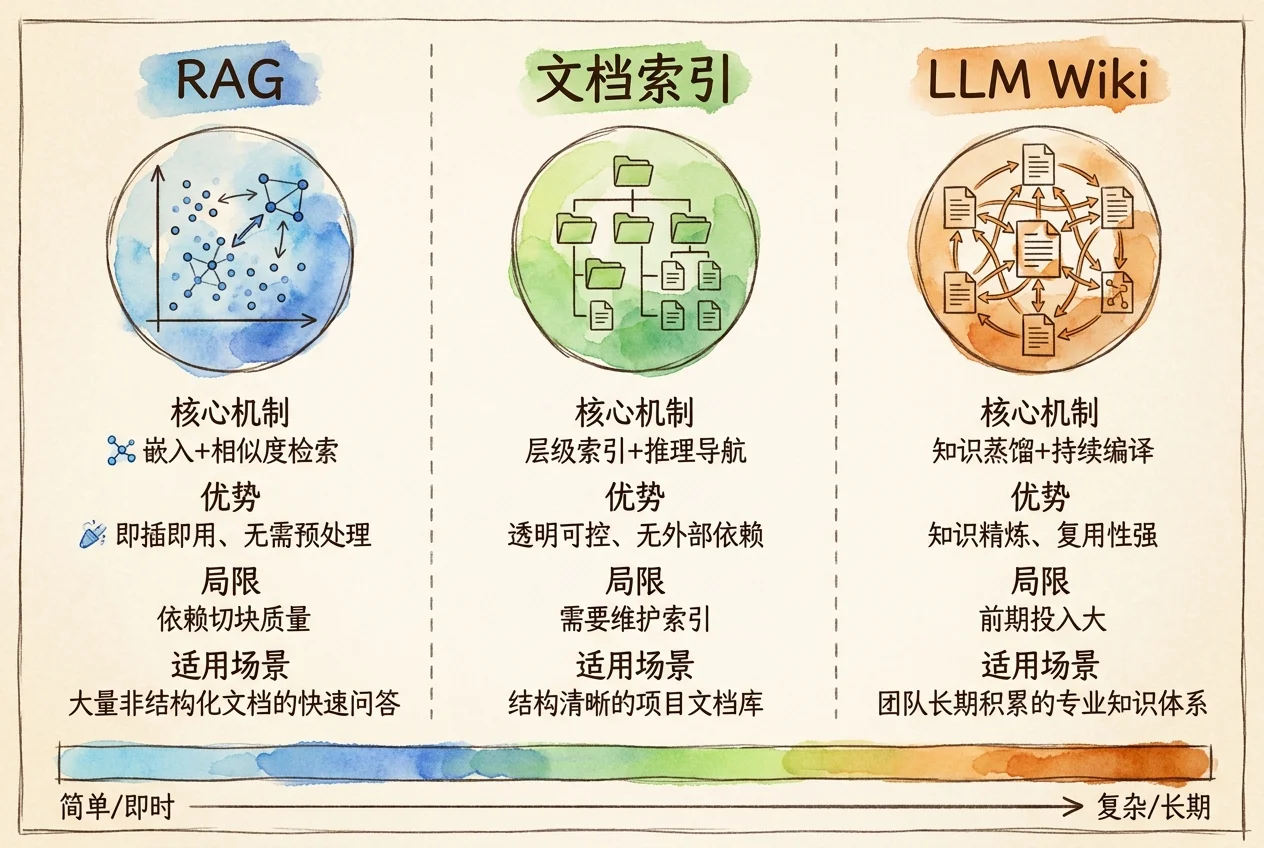
三种知识库构建方法各有适用场景。选择的关键不在于哪种方法更先进,而在于哪种方法与你的文档规模、团队能力和使用频率最匹配。
系统对比
下表从七个维度对比三种方法的核心差异:
| 维度 | RAG(嵌入检索) | 文档索引(推理检索) | LLM Wiki(知识编译) |
|---|---|---|---|
| 技术复杂度 | 高:嵌入模型 + 向量数据库 + 检索管线 | 低:纯文件系统 + 索引文件 | 中:文件系统 + LLM 编译流程 |
| 基础设施 | 向量数据库、嵌入服务、可能需 GPU | 无额外基础设施 | 无额外基础设施,摄入阶段消耗大量 token |
| 知识积累 | 无:每次查询从零检索 | 弱:索引本身不积累知识 | 强:每次摄入在已有知识上叠加 |
| 文档规模 | 大:千篇至百万篇 | 中小:20-500 篇 | 中:50-200 篇源文档 |
| 维护成本 | 中:新文档需分块、嵌入、入库 | 低:更新索引文件即可 | 中:新文档触发 wiki 页面级联更新 |
| 查询准确性 | 中:受分块质量和嵌入模型影响 | 高:结构化文档可达 98%+ | 高:知识经编译和交叉验证 |
| 典型场景 | 海量文档的语义模糊查询 | 结构清晰的专业文档精准定位 | 长期维护、需要知识综合与矛盾检测 |
选择指南
选择方法时,按以下决策路径逐步排除:
- 文档总量是否超过 500 篇,或需要语义模糊匹配?是 → RAG
- 是否需要长期知识积累、矛盾检测、交叉引用?是 → LLM Wiki
- 以上均不需要 → 文档索引(最轻量起点)
三种方法对应的典型金融场景:
| 方法 | 典型场景 | 选择理由 |
|---|---|---|
| 文档索引 | 投研团队内部研报(< 100 篇)、企业合规文档库 | 零基础设施投入,索引文件 + 目录结构即可运行 |
| RAG | 全市场研报库(数千至数万篇)、学术论文数据库 | 用户可能用不同表述检索同一概念,需要向量语义匹配 |
| LLM Wiki | 宏观研究团队跟踪央行政策演变、行业知识网络 | 需要持续追踪演变、发现矛盾、建立交叉引用 |
三种方法不互斥。成熟的知识库系统通常混合使用:用 Wiki 模式编译核心知识,用 RAG 处理溢出的大规模语料,用文档索引管理结构化的参考文档。先从最轻量的方案开始,在实际需求驱动下逐步叠加。
常见误区
RAG 的核心能力是语义检索,但它无状态、无知识积累、跨文档综合弱。分析师需要长期追踪一家公司的基本面变化时,RAG 每次查询都从零检索,无法形成递增的分析视角。正确做法是先明确知识管理目标,再选择匹配方案。
无论选择哪种方法,文档本身的组织质量都是上限。RAG 中糟糕的分块策略破坏上下文完整性;文档索引中混乱的目录结构让索引失去导航价值;Wiki 中标注不清的原始资料导致编译产物含糊不清。投入时间整理文档结构,回报远大于调优检索算法。
误区 3:知识库建好就不用维护。 文档会过时,原有分析可能被新数据推翻。RAG 系统需要定期清理过时文档;文档索引需要同步更新索引文件;Wiki 系统需要定期运行 Lint 审校。文档更新频繁的场景(如投研团队每周收到新研报),建议每周执行一次知识库维护。
误区 4:追求技术复杂度而非匹配场景。 一个只有 50 份内部研报的团队,用文档索引方法花 30 分钟整理好目录结构就能用。技术选型的原则是用最简单的方案满足当前需求,在实际瓶颈出现时再升级。
误区 5:把所有文档都放入同一个知识库。 不同类型的文档有不同的使用模式。财报需要精确查找特定指标,行业报告需要跨文档综合分析,政策法规需要追踪条文变更。按使用模式分库管理。
误区 6:过度依赖向量相似度。 查询”2024 年 LPR 调整的影响”,向量检索可能返回”2023 年 LPR 调整的影响”——语义高度相似但年份错误。金融文档中年份、公司代码等字段的精确匹配同样重要,应将向量检索与元数据过滤结合。
先用文档索引跑通流程,遇到规模瓶颈再引入 RAG,需要知识积累时叠加 Wiki。技术选型跟着实际痛点走,不跟着技术复杂度走。