8.6 设计模式与常见误区
面向经管学生、研究者与从业者的 AI 智能体设计教材
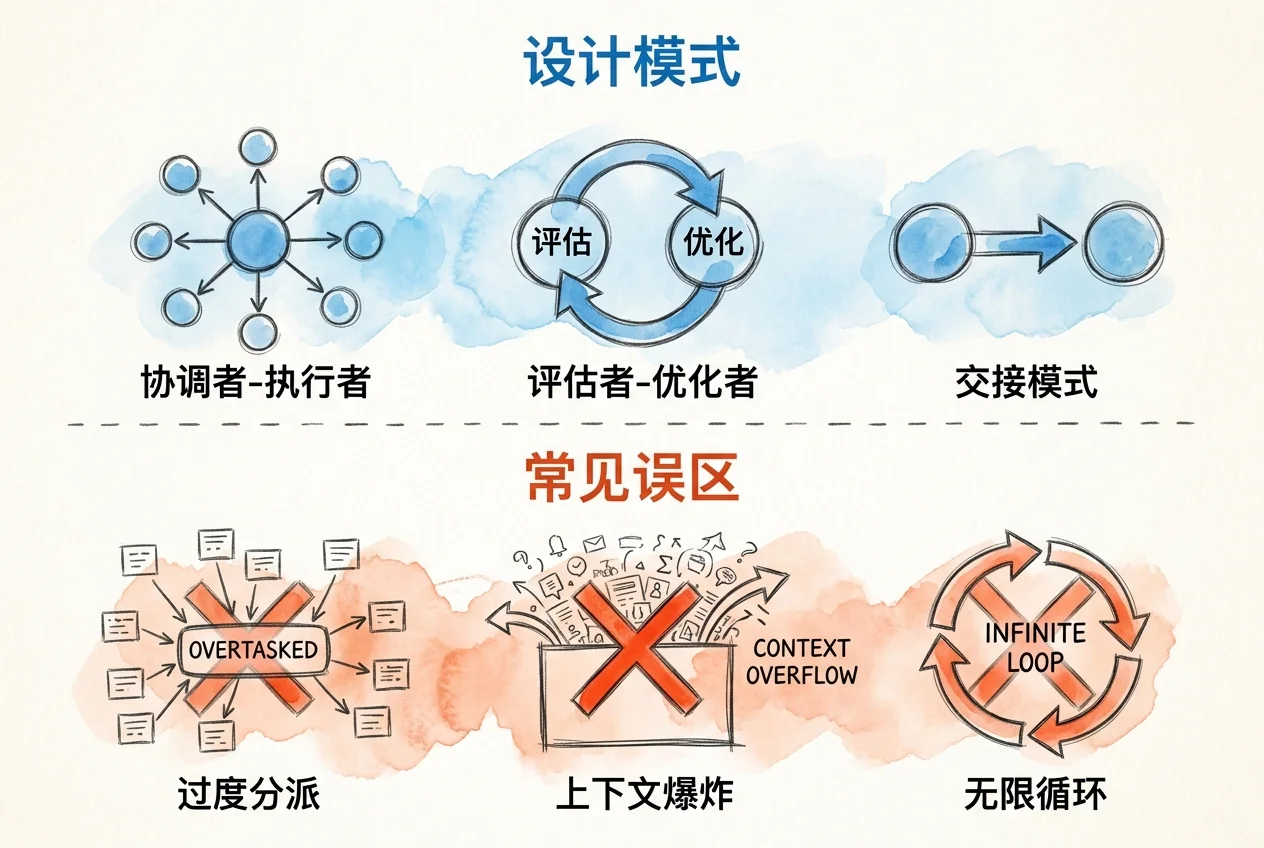
在子代理的实际应用中,已经形成了几种常见设计模式。设计模式的价值,不在命名,而在少走弯路。
协调者-执行者模式
协调者-执行者(Orchestrator-Workers)是最常见的多子代理模式。主代理作为协调者,负责拆分任务、分派工作和整合结果;多个子代理作为执行者,各自完成分配的子任务。
主代理(协调者)
├── 拆分任务
├── 分派给子代理
├── 收集结果
└── 整合报告
子代理 A(执行者)→ 盈利能力分析
子代理 B(执行者)→ 偿债能力分析
子代理 C(执行者)→ 运营效率分析适用场景:任务可以自然拆分为多个独立的子任务,每个子任务的执行方法相似但输入不同。
金融应用:多公司对比分析、多市场数据采集、多维度风险评估。
评估者-优化者模式
评估者-优化者(Evaluator-Optimizer)模式中,一个子代理负责生成初稿,另一个负责评估并提出改进建议。两者交替工作,逐步提升输出质量。
循环流程:
生成者子代理 → 产出初稿
评估者子代理 → 审查并反馈
生成者子代理 → 根据反馈修改
评估者子代理 → 再次审查
... (直到质量达标或达到最大轮次)适用场景:对输出质量有严格要求,需要多轮打磨才能达标。
金融应用:研究报告撰写(分析师写初稿、合规团队审查)、投资建议生成(策略组产出、风控组评估)。
没有停止条件的优化,不是打磨,而是空转。 常见做法是设置最大迭代次数,通常为 2-3 轮,或定义可量化的通过标准。
交接模式
交接(Handoff)模式中,子代理之间按流水线方式传递任务。上游子代理的输出是下游子代理的输入,每个子代理完成一个阶段的工作后交给下一个。
子代理 A(数据采集)
→ 输出 temp/raw-data.json
→ 子代理 B(指标计算)
→ 输出 temp/calculated-ratios.json
→ 子代理 C(报告撰写)
→ 输出 output/final-report.md适用场景:任务由多个有依赖关系的阶段组成,每个阶段需要不同的专业能力。
金融应用:从年报 PDF 提取数据,再进行清洗和计算,最后生成分析报告。这三个阶段分别需要文档解析、数值计算和文本撰写能力。
交接模式和协调者 - 执行者模式的区别在于,前者是串行推进,后者通常用于并行分工。选择哪种模式,取决于子任务之间是否存在依赖关系。
隔离高频操作模式
子代理最直接的用途之一,是把产生大量输出的操作隔离到独立上下文中。运行测试套件、抓取网页文档、处理日志文件,这些操作可能输出数千 token,但你真正需要的往往只是几行摘要。
用子代理运行完整的测试套件,只报告失败的测试及其错误信息把这类操作委派给子代理后,冗长的原始输出留在子代理的上下文里,主对话只收到精炼的结果。这对金融数据处理场景尤其有用:批量解析上百份公告、清洗大规模交易日志、跑回测报告,都适合用这种方式隔离。
链式子代理模式
对于多步骤工作流,可以让主代理按顺序调用多个子代理,前一个子代理的输出作为后一个的输入上下文。
先用 code-reviewer 子代理找出性能问题,然后用 optimizer 子代理修复这些问题在 CLAUDE.md 中定义工作流步骤,主代理会按顺序依次创建子代理执行。每个子代理完成后将结果返回主代理,主代理再把相关上下文传给下一个。
这种模式适合需要多种专业能力接力完成的任务:先用数据采集子代理获取财报,再用分析子代理计算指标,最后用写作子代理生成报告。与交接模式的区别在于,链式子代理由主代理显式编排调用顺序,而交接模式更强调通过文件系统自动串联。
何时委派给子代理
不是所有任务都适合交给子代理。官方文档给出了明确的选择指南:
适合在主对话中完成的任务:
- 需要频繁来回沟通或迭代调整的工作
- 多个阶段共享大量上下文(规划 → 实现 → 测试属于同一流程)
- 你需要全程监控每一步的执行
适合委派给子代理的任务:
- 有大量探索或搜索操作(避免污染主对话上下文)
- 可以并行处理的独立工作
- 需要限制特定工具权限或执行模式
- 任务本身自成体系,能以摘要形式返回结果
如果一个任务的完整输出你并不需要看到,只需要知道结论,那它就适合交给子代理。反过来,如果你需要在执行过程中随时调整方向,就留在主对话里做。
还有两个容易混淆的替代方案:如果你想要可复用的提示词或工作流、但不需要隔离上下文,用 Skills 更合适;如果只是对当前对话中已有内容提一个快速问题,可以用 /btw 命令(“by the way” 的缩写)——它能看到完整上下文但不调用任何工具,回答也不会写入对话历史,是最轻量的一次性询问方式。
如果需要阻止某个子代理被调用,可以在 settings.json 的 permissions.deny 中添加 "Agent(subagent-name)",或在启动时传入 --disallowedTools "Agent(name)"。
反模式警示
以下做法在实践中证明效果不佳:
过度生成子代理
将每个微小步骤都交给独立的子代理处理,会导致子代理数量膨胀。创建和协调子代理本身有成本,当子任务过于简单时,如读取一个文件、转换一个格式,直接在主代理中执行更高效。
只有真正消耗上下文、或能并行推进的任务,才值得拆成子代理。
上下文爆炸
让子代理返回完整分析结果而不是状态摘要,会让大量内容回流到主代理的上下文里,导致上下文窗口迅速占满。这是上下文工程中最常见的失误:没有在信息流入主代理之前做好过滤。解决方法很直接,严格执行文件化传递策略,把详细结果写入文件,只返回 1-2 句话的摘要。
无限循环
在评估者-优化者模式中,没有设置停止条件,两个子代理反复迭代,永远达不到完美状态。
解决方法:设置最大迭代次数,并定义可衡量的通过标准。
子代理之间过度协调
Anthropic 在早期版本中遇到过一个问题:多个子代理之间频繁互相更新状态,结果互相拖慢。子代理之间每多一层通信,延迟和出错概率都会增加。 设计原则是让子代理各自独立完成任务,通过文件系统交换结果,而不是在运行中互相等待。
为不存在的信息无休止搜索
子代理有时会对一条不存在的数据反复搜索,换不同关键词尝试,消耗大量 token 却没有结果。Anthropic 的做法是在提示词中设置搜索轮次上限:如果连续 3 次搜索都没有找到目标信息,就停下来报告未找到,而不是继续尝试。在金融数据采集中,这种情况尤其常见:某些非上市公司或早年数据根本不在公开数据库里,子代理要及时停止搜索。
设计检查清单
在设计多子代理工作流时,用这份清单确认每个关键环节:
| 检查项 | 问题 |
|---|---|
| 角色定义 | 每个子代理的职责是否明确?是否存在职责重叠? |
| 工具配置 | 每个子代理是否只配置了完成任务所需的最小工具集? |
| 输入输出 | 输入来源和输出路径是否都已约定?输出格式是否标准化? |
| 上下文管理 | 子代理是否将结果保存到文件而非直接返回? |
| 依赖关系 | 子任务之间的依赖关系是否清晰?能并行的是否已并行? |
| 错误处理 | 子代理失败时的恢复策略是什么? |
| 停止条件 | 迭代类模式是否设置了最大轮次? |
| 成本控制 | 子代理数量是否合理?模型选择是否匹配任务难度? |
评估多子代理系统
多智能体系统不像传统程序那样总会走同一条路径。面对同一个输入,不同子代理可能查不同数量的来源、走不同路线,但最终都给出合理答案。所以评估的重点不是检查每一步是否按预设执行,而是看最终结果对不对、过程是否合理。
Anthropic 在构建多智能体研究系统时总结了三条评估经验:
尽早做小规模评估
在早期阶段,很多提示词调整的效果很大,可能一下把成功率从 30% 拉到 80%。这时候不需要上百题的大型测试集,20 个能代表真实使用场景的问题,往往已经足够判断改动有没有效果。
用 LLM 做评委
研究类产出通常是自由文本,很难用规则程序判断质量。Anthropic 用另一个 LLM 作为评委,根据评分标准检查事实准确性、引用准确性、完整性和来源质量。
在金融分析场景中,可以让一个独立的评估子代理检查分析报告:数据是否正确引用、计算是否交叉验证、结论是否有依据支撑。
注意涌现行为
多智能体系统会出现涌现行为:主代理的提示词稍做修改,所有子代理的行为都可能一起变化。最好的提示词不是一连串僵化指令,而是清楚的协作框架、分工方式和质量标准。
涌现行为(Emergent Behavior)指系统整体表现出单个组件不具备的行为特征。在多智能体系统中,主代理的一个小改动可能通过任务分派链路放大,导致所有子代理的行为模式同时偏移。这不一定是坏事,但需要通过评估来监控。
设计多子代理系统时,可以先从 2 个子代理开始验证核心流程,确认正常后再逐步增加。一次性构建包含十余个子代理的复杂系统,调试成本会很高。