21.4 连接微信
面向经管学生、研究者与从业者的 AI 智能体设计教材
管家已在后台运行,但尚无对外入口。下面完成微信接入的配置,使其具备对外通信能力。
OpenClaw 也支持飞书、企业微信、QQ、钉钉等其他国内主流消息平台,配置方式各有插件文档可循。本书以微信为案例展开,因为它是目前覆盖人群最广、最容易让管家”出现在身边”的渠道。
安装微信官方插件
微信渠道由腾讯官方提供,一条命令即可触发安装:
npx -y @tencent-weixin/openclaw-weixin-cli@latest install
命令拆解
npx:Node 自带的一次性执行工具,不需要把包装到全局环境,临时下载下来运行一次即可-y:默认对所有确认问题回答 yes,自动跳过交互式提示@tencent-weixin/openclaw-weixin-cli@latest:腾讯官方组织@tencent-weixin下发布的微信插件 CLI 包,@latest取最新版本install:触发该插件的安装与初始化流程
命令执行后,终端会输出一张二维码。用预备好的微信账号扫码完成授权,插件会将该微信身份绑定至管家,并在本地配置文件中保存登录凭证。
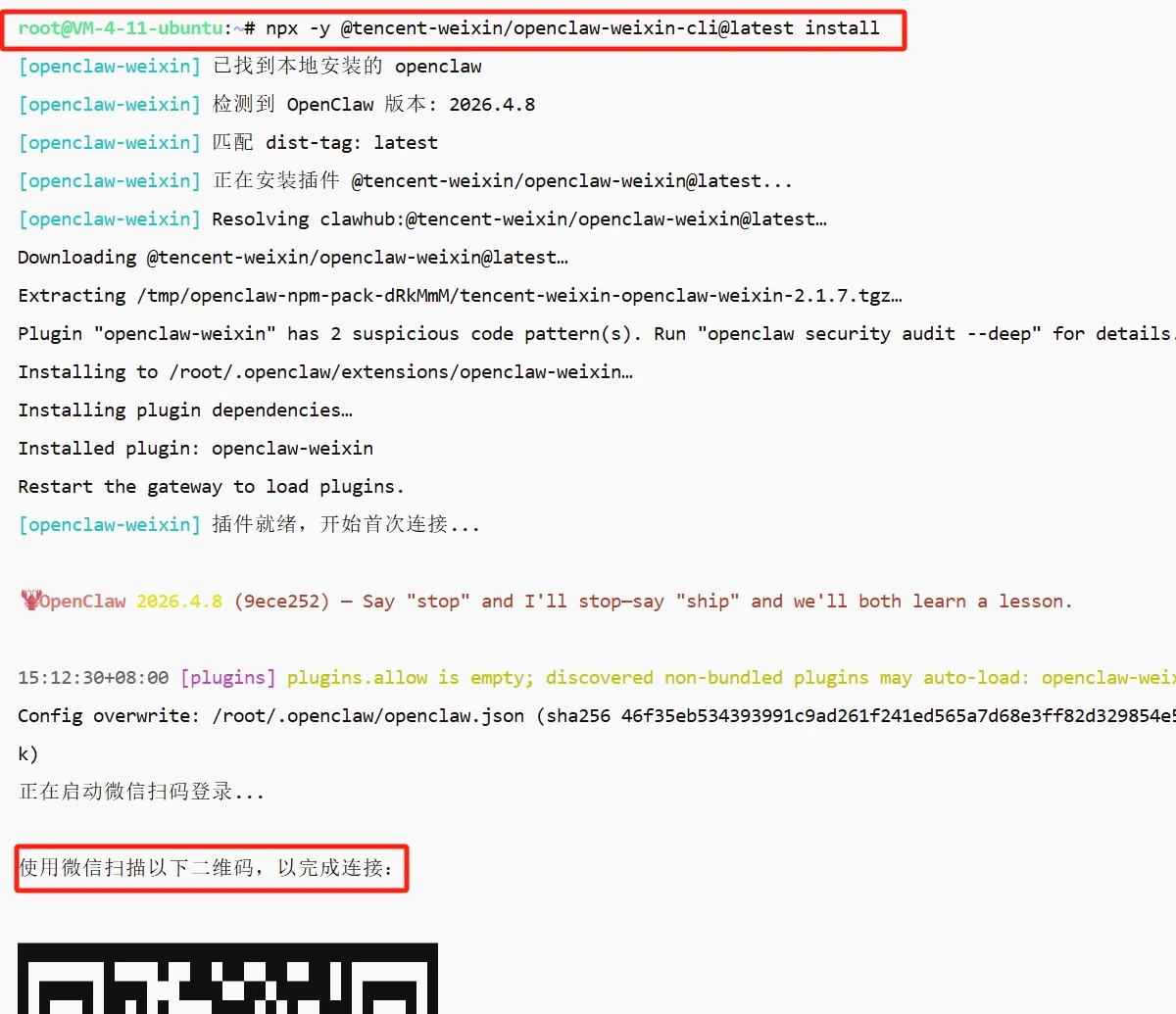
扫码成功后,终端会显示登录微信的昵称与绑定状态。登录凭证已保存,但此时微信渠道尚未在运行时生效。新安装的渠道插件要被 Gateway(消息网关,负责接收和分发各渠道消息的核心服务)加载,必须重启一次:
openclaw gateway restart重启一般几秒完成。Gateway 起来之后,微信渠道才会真正挂载并开始监听消息。
首次验证:发一条消息确认通路
绑定完成后做一次最简单的验证:向管家账号发送一条消息,正常情况下,管家会在数秒内返回一条问候或自我介绍。出现回复即表明消息通路已打通,管家可以正常接收并回应微信消息。
如长时间无回复,登录到云服务器上执行以下命令确认 Gateway 是否正常运行:
openclaw gateway status # 验证 Openclaw 是否在运行输出会显示 Gateway 的运行状态与各渠道的连接情况。若 Gateway 未运行或微信渠道处于断开状态,查看终端日志或重新执行 openclaw configure 进入渠道配置项排查。
常见故障
长时间无回复,通常是以下三类原因之一:
- 登录态失效:长时间运行后微信侧登录态可能过期,重新执行上面的
npx安装命令扫码即可 - 云服务器网络异常:检查云服务器能否访问外网,特别注意安全组放行情况
- API Key 额度用尽:到模型厂商的后台查看额度,充值或切换厂商
- 云服务器关机或重启失败:管家依赖云服务器持续在线,机器一旦关机,整条链路就断了