13.1 为什么评估是第二篇的收束机制
面向经管学生、研究者与从业者的 AI 智能体设计教材
13.1 为什么评估是第二篇的收束机制
评估不是重新描述整套工作流,而是把问题落到可检查的结构件上,判断它最先出在哪一层。
评估在检查什么
把工作流拆开看,常见的可评估结构件大致如下:
| 结构件 | 在系统里的作用 | 评估时的检查点 |
|---|---|---|
| 任务说明与验收条件 | 定义本轮要交付什么 | 任务目标是否清楚,输出是否符合预期 |
| 规则文件 | 统一约束术语、格式和边界 | 约束是否生效,违反时是否被拦截 |
| Skills | 封装可复用流程与工具权限 | 触发是否准确,输出是否稳定复现 |
| 多智能体协作 | 分配角色与上下文 | 分工是否合理,上下文是否正确传递 |
| Hooks | 在关键节点执行门禁和校验 | 关键节点是否被拦截,校验结果是否回灌 |
| Git 基线 | 提供版本边界和回退路径 | 改动是否可追溯,回退是否可执行 |
如果没有评估,这些结构件虽已配置,却不知道是否正确。任务说明写了验收条件,没人检查输出是否真的满足;Skill 设置了触发短语,不清楚实际触发率;Hook 配置了门禁脚本,也没有测过误拦截和漏拦截的比例。
评估不是附属动作
一个常见误解,是把评估当成开发完成后的补充步骤:系统构建完成后,最后再执行一遍测试看分数。这样做的问题是,等到最后才发现问题,往往已很难判断问题出在哪一层。
更有效的做法,是把评估嵌入开发过程。每修改一个 Skill,就执行一次触发准确率测试;每调整一次多代理分工,就检查上下文传递是否完整;每次提交前,都用 Hook 执行格式和内容校验。评估承担的是持续反馈,而不是事后验收。
评估的作用不是给系统打分,而是让改动有据可循。改了提示词,要能看到输出质量的变化;改了 Skill 结构,要能验证触发稳定性是否提升;改了代理分工,要能确认整体行为没有回归。没有评估,优化就失去了依据。
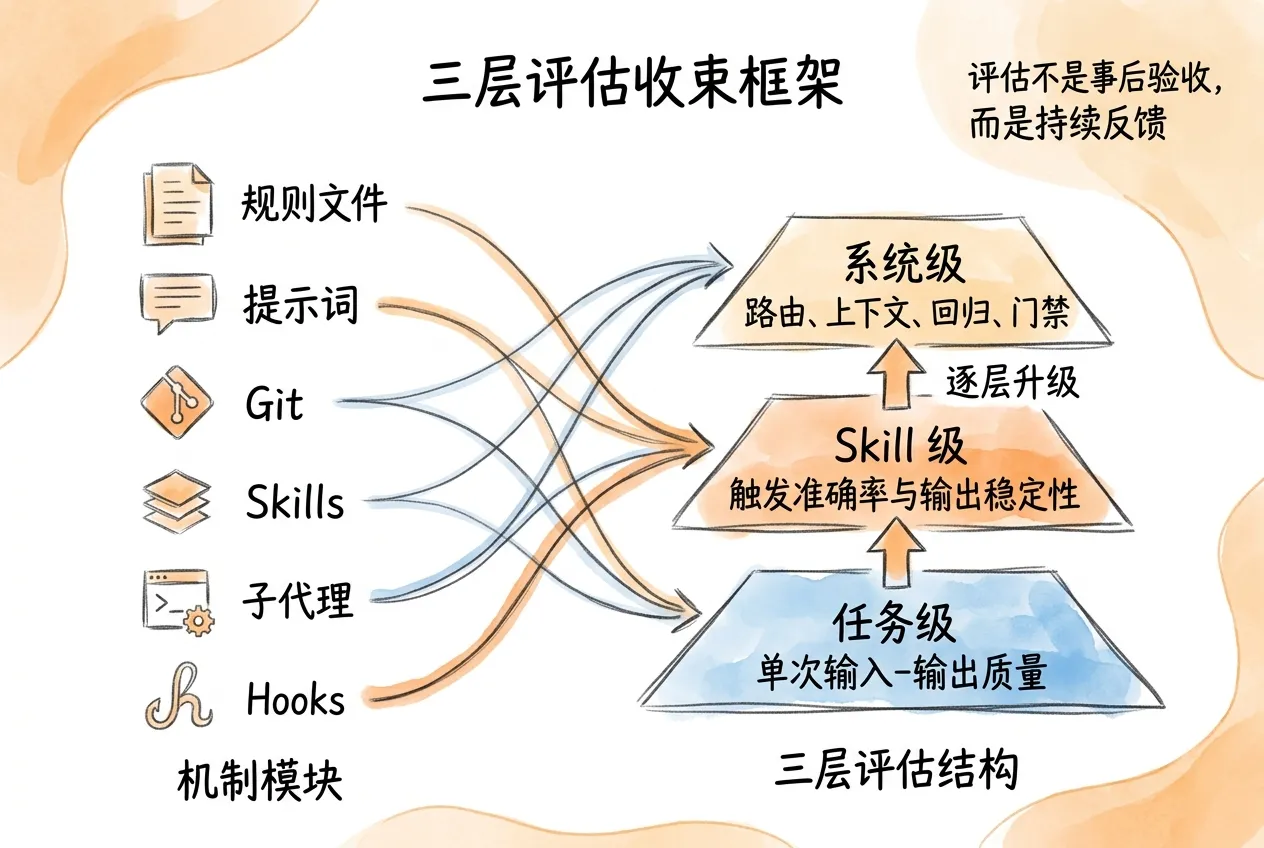
三层评估对象
并非所有问题都该用同一种方式检查。一个智能体工作流产出不合格结果,原因通常分布在三个层面:
任务级:这一次任务的输入、约束或验收条件有问题。比如任务说明未明确输出格式,或者提供的参考资料不够。
Skill 级:封装好的工作流在反复执行时不稳定。比如同一个 Skill 有时能正确触发,有时触发了但加载的参考文件不对。
系统级:多个组件协作时出现漂移、冲突或回归。比如多个代理并行执行后,结果合并逻辑有缺陷;或者修复了一个问题,却破坏了之前正常的功能。
| 层级 | 评估对象 | 典型问题 | 优先检查 |
|---|---|---|---|
| 任务级 | 单次输入-输出 | 输出缺项、格式错误、事实不准 | 任务定义、验收条件、示例 |
| Skill 级 | 封装后的工作流 | 触发不稳、输出骨架不一致 | description、工具权限、参考文件 |
| 系统级 | 多组件协作 | 路由错误、上下文丢失、回归 | 代理分工、Hooks、Git 基线 |
这三层不是替代关系,而是递进关系。任务级评估是基础;如果单次任务都无法高质量完成,讨论 Skill 稳定性没有意义。Skill 级评估建立在任务级通过的前提上;单次能高质量完成,但重复执行时质量不一致,说明封装存在问题。系统级评估关注长期运行和多组件协作;单个 Skill 都稳定,但组合后出了问题,就需要在系统层继续排查。
本节一句话总结: 评估不是开发完成后的附属步骤,而是把整套工作流串成工程闭环的核心动作。