21.1 OpenClaw:开源 AI 管家的崛起
面向经管学生、研究者与从业者的 AI 智能体设计教材
一个独立开发者的项目,四个月席卷 GitHub
2025 年 11 月 24 日,奥地利独立开发者 Peter Steinberger(GitHub 账号 @steipete)把一个雏形版本推上 GitHub,取名 Clawdbot。它脱胎于作者此前自用的个人虚拟助手 Clawd,一个能把大模型挂到日常聊天软件里、随时发消息使唤的小工具。四个月后,它以 OpenClaw 之名成为 GitHub 上 star 数增长最快的开源项目之一。
项目两个月内经历了两次改名:2026 年 1 月 27 日因 Anthropic 商标投诉先改为 Moltbot,仅三天后又因 Moltbot 读起来拗口、于 1 月 30 日定为 OpenClaw,star 数在短时间内大幅跃升。2026 年 2 月 14 日 Steinberger 宣布加入 OpenAI,项目转由一个非营利基金会承接维护,保持开源与独立。
Star 增长曲线

从一个周末项目到 GitHub 上现象级的开源仓库,OpenClaw 用了不到四个月。关键里程碑如下:
| 时间节点 | 阶段 | 说明 |
|---|---|---|
| 2025-11-24 | 项目首发 | 以 Clawdbot 之名首次上线 |
| 2026-01 初 | 开始扩散 | 开发者圈子内关注度逐步扩散 |
| 2026-01-30 | 品牌重塑 | 更名 OpenClaw,star 数大幅跃升 |
| 2026-02 中下旬 | 快速增长 | 数周内持续攀升,曲线陡峭 |
| 2026-03 | 持续攀升 | 累积成为 2026 年初增长最快的开源仓库之一 |
| 2026-04 当前 | 稳态维护 | 收藏数达到 36 万以上,开源许可,社区维护 |
以下链接贯穿后续章节,建议收藏备用。
- GitHub 主仓库:https://github.com/openclaw/openclaw
- 官方文档站:https://docs.openclaw.ai
- ClawHub 技能库官方站:https://clawhub.ai
- ClawHub GitHub 仓库:https://github.com/openclaw/clawhub
国内养虾潮
OpenClaw 的项目 logo 是一只红色卡通龙虾(lobster),官方标语是 “The lobster way”。中文开发者社区很快把部署、配置、训练、调用这只龙虾的过程亲切地称为养虾,把 OpenClaw 实例称为龙虾或小龙虾。这一称呼随项目热度扩散,逐渐被主流技术社区采用。
国内的养虾潮从 2026 年 2 月起逐步扩大。国内主流云厂商陆续上线托管服务,社区中也出现了面向个人用户的代装与托管服务。
OpenClaw 在国内有三种部署形态:
- 本地桌面应用:封装成安装包下载到自己电脑直接用,以腾讯 QClaw 为代表
- 云端托管:龙虾跑在厂商服务器上,注册账号即可使用,由各家云厂商提供
- 自建:自己用开源版本装到任意一台 Linux 机器上(云服务器、自己的笔记本、家里的小主机都行)
前两类由国内厂商承接,下表列出主要产品。第三类自建是本书后续重点讲解的路径。
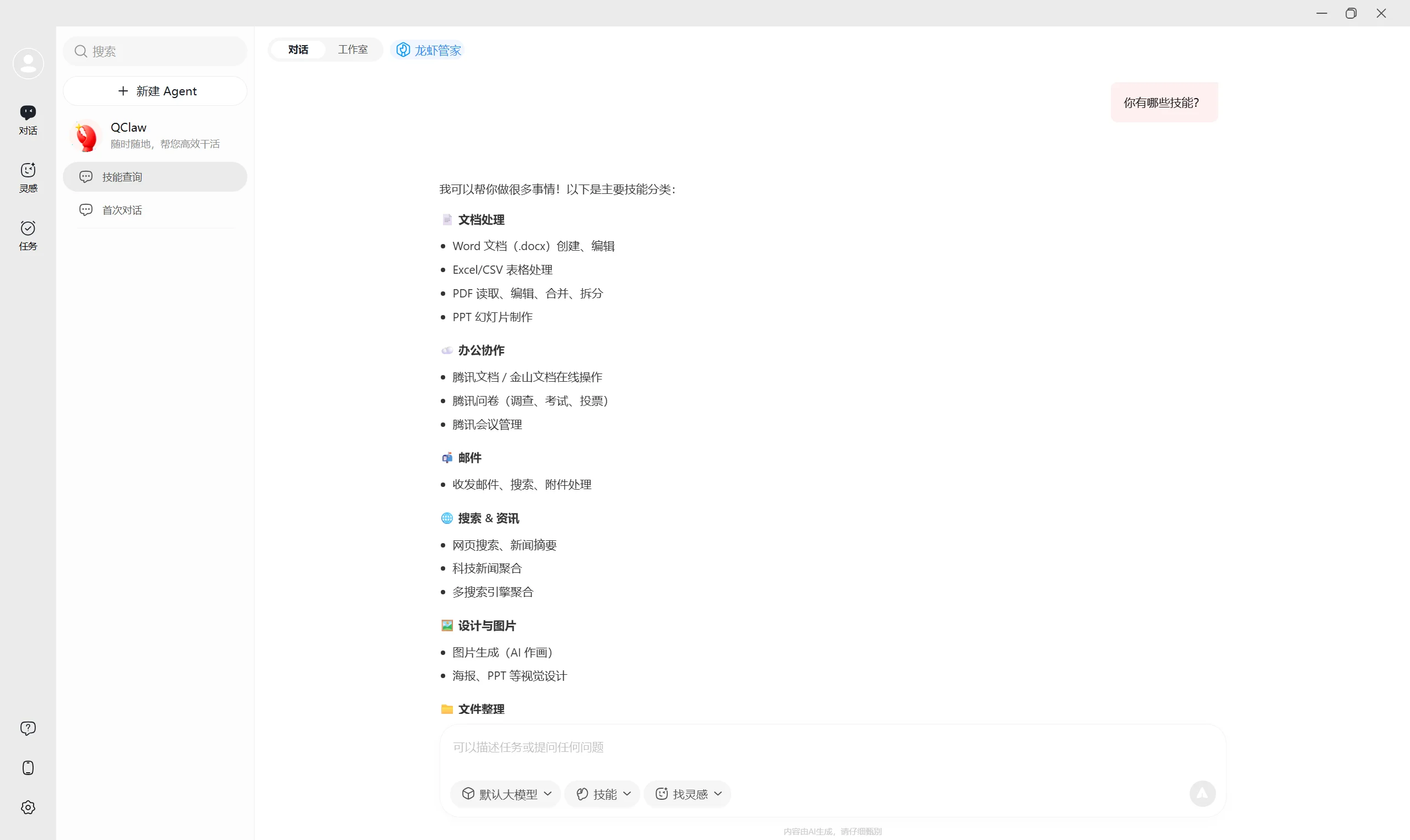
以腾讯 QClaw 为例(属于本地桌面应用),下载安装后的桌面客户端界面如下,内置文档处理、办公协作、邮件、搜索、设计等多类 Skills:
| 服务名 | 提供方 | 部署形态 | 定位 |
|---|---|---|---|
| QClaw | 腾讯 | 本地桌面应用 | 下载安装包装在自己电脑上,集成微信、QQ |
| ClawPro | 腾讯云 | 云端托管 | 面向企业的管控平台版本 |
| ArkClaw | 字节·火山引擎 | 云端托管 | 飞书深度整合 |
| CoPaw | 阿里 | 云端托管 | 钉钉联动,支持阿里云 |
| KimiClaw | 月之暗面 | 云端托管 | 长上下文窗口 |
| MaxClaw | MiniMax | 云端托管 | 零代码配置 |
以上信息以各平台官方页面为准,产品功能和定价可能随版本更新变化。
从工具到管家:一种新的形态
OpenClaw 在几个月内获得如此关注度,并非因为它是又一个 CLI agent 的包装版本,而是因为它提出了一种新的形态:常驻智能体(always-on agent)。要理解这一形态,把它与本书读者最熟悉的 Opencode 做一组直接对比即可:
| 维度 | Opencode | OpenClaw |
|---|---|---|
| 运行形态 | 本地协作工具,在项目目录中打开 | 部署在某台机器上的后台服务 |
| 上下文范式 | 按项目隔离,自动加载该目录的规则文件、Skills、记忆 | 个人级工作区,跨项目共用人格与记忆 |
| 在场要求 | 必须在该项目所在的电脑路径中打开 | 部署机器开着即可,从任意设备的消息工具远程触发 |
| 生命周期 | 关闭终端即停 | 部署机器开机期间持续在后台运行 |
| 主动能力 | 被动响应(/loop 可定时执行,但需保持终端开着) |
可定时主动执行任务,并通过消息渠道主动推送 |
| 典型用法 | 项目内深度工作(写研报、做分析) | 跨设备日常调度、定时巡查、消息中继 |
这种持续在线的形态,是 OpenClaw 获得关注的根源:交互模式从”打开工具、提问、关闭”变成了”随时发消息、随时收回应”。
守护进程是一种在系统后台持续运行、不依赖人为交互的程序。它没有图形界面,不占用终端窗口,只要操作系统在运行,它就持续存在。邮件客户端的后台同步、云盘的自动备份都属于守护进程。OpenClaw 启动后也是这类进程,启动一次之后,它就在后台等待消息到达。需要注意:守护进程依然依赖宿主机器,机器关机或断电,进程也会随之终止。
OpenClaw 不是 Opencode 的替代品,两者是协作关系。管家常驻后台负责调度,专家按需进入项目目录做深度工作。