7.3 触发机制与渐进式披露
面向经管学生、研究者与从业者的 AI 智能体设计教材
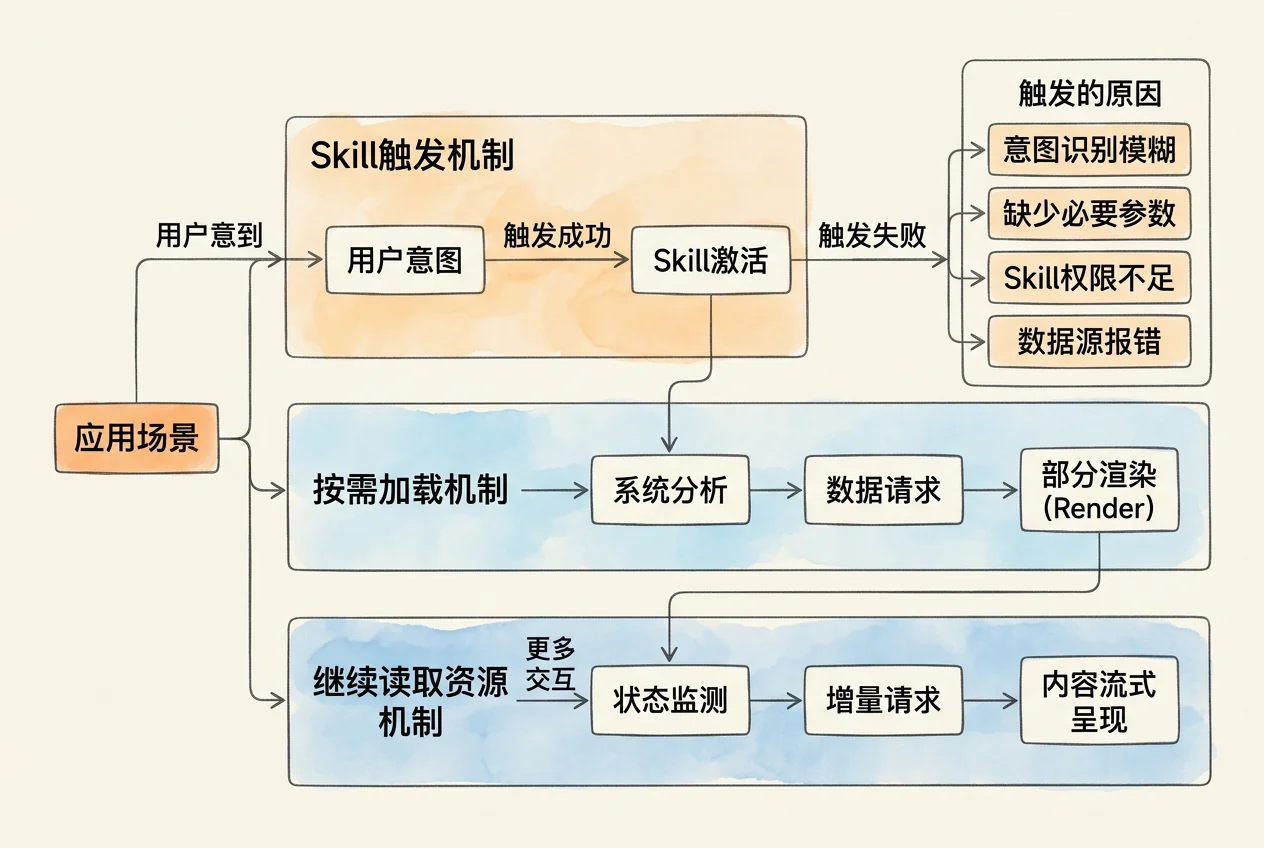
理解了 Skill 的结构之后,再看系统如何判定何时使用它。
三阶段触发流程
在 Claude 的实现中,Skill 的加载分为三个阶段:
| 阶段 | 动作 | 读取内容 | 上下文开销 |
|---|---|---|---|
| 发现 | 扫描可用 Skill | name 和 description |
极小(约 100 tokens / Skill) |
| 匹配 | 判断与当前任务的相关性 | 元数据对比 | 小 |
| 加载 | 读取正文与附加资源 | SKILL.md 正文、scripts/、references/ | 按需增长 |
系统启动时,会把所有可用 Skill frontmatter 加载到上下文中。每个 Skill frontmatter 约 100 tokens。当用户提出请求,系统根据 name 和 description 判断哪些 Skill 与当前任务相关,相关 Skill 才会进入正文读取阶段。
渐进式披露的三层模型
这个机制的核心原则是渐进式披露(Progressive Disclosure)。它不是一次性把所有内容加载到上下文,而是分层按需展开。
- 定义:Skill 采用的三层信息加载策略。先暴露少量元数据,确认相关后再读取正文,必要时再访问附加文件。
- 设计目标:在保持专业能力的同时,最小化 token 消耗。
三层模型的具体分工:
| 层级 | 内容 | 加载时机 | 典型大小 |
|---|---|---|---|
| 第一层 | YAML frontmatter(name + description) | 始终加载到系统提示中 | ~100 tokens |
| 第二层 | SKILL.md 正文(步骤、示例、错误处理) | 系统判断相关时加载 | 数百至数千 tokens |
| 第三层 | 链接文件(scripts/、references/、assets/) | 执行过程中按需读取 | 视文件大小而定 |
因此,安装 20 个 Skill 也不会把 20 份完整说明都塞进上下文。它只加载 20 份 frontmatter(约 2000 tokens),然后根据当前任务选择性地展开 1 - 2 个 Skill 的正文。
description 决定触发质量
渐进式披露说明:description 的质量直接决定触发是否准确。
读取正文前,系统只能依靠 name 和 description 做判断。如果 description 写得很空,例如只写“一个有用的分析 Skill”,系统就无法区分它适用于财报分析、舆情分析还是政策分析。描述越模糊,触发越不稳定。
如果不确定 Skill 的触发效果,可以直接问智能体:
你什么时候会使用 quarterly-earnings-summary 这个 Skill?智能体会根据 description 回答它的理解。如果回答与你的预期不符,说明 description 需要修改。
触发不良的两种信号
触发问题通常表现为两种:
触发不足——Skill 在该用的时候没有被加载:
- 用户明确提到相关任务,但 Skill 不响应
- 用户需要手动启用 Skill
- 典型原因:description 太模糊,缺少用户实际会说的短语
触发过度——Skill 在不该用的时候被加载:
- 无关任务也触发了该 Skill
- 用户主动禁用 Skill
- 典型原因:description 太宽泛,没有界定适用边界
| 问题 | 表现 | 应对方法 |
|---|---|---|
| 触发不足 | 相关任务不触发 | 在 description 中增加具体的触发短语和关键词 |
| 触发过度 | 无关任务也触发 | 在 description 中添加否定条件,收窄适用范围 |
否定条件的写法示例:
description: >
分析 CSV 格式的财务数据,执行统计建模和回归分析。
当用户要求数据分析、财务建模、回归检验时使用。
不用于简单的数据可视化(请使用 data-viz Skill)。因此,编写 Skill 时有一个实用原则:把最关键的触发信息写在 description 中,把详细执行步骤留给正文。先让系统准确判断该不该用,再让正文回答用了以后怎么做。