16.3 从模糊需求到清晰方案
面向经管学生、研究者与从业者的 AI 智能体设计教材
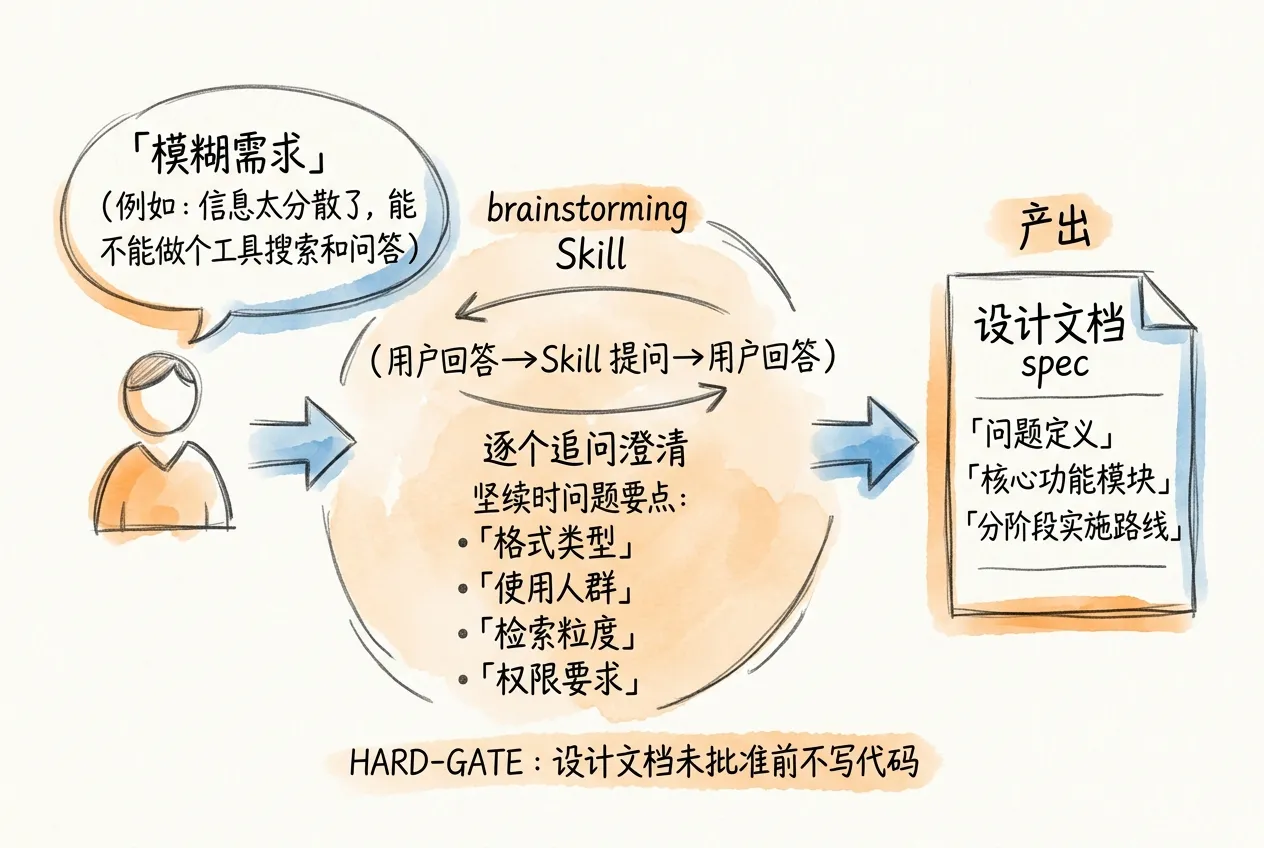
用户有一个模糊想法时,第一反应往往是打开编辑器开始写代码。brainstorming Skill 的设计意图恰好相反——它强制在写代码之前完成需求澄清和方案设计。
本章案例从零开始,没有既有代码库可调研。但在提需求之前,仍需确认技术栈约束——团队熟悉的框架、基础设施限制、数据合规要求——这些构成 brainstorming 的输入条件。对于接手已有项目,superpowers 的 brainstorming 同样会在 Explore 阶段读取代码库;如需更专门的术语管理,可选用 mattpocock/skills 的 grill-with-docs。
开发流程从一句日常口语开始。不需要写正式的需求文档,把想解决的问题说清楚即可:
我们部门每天要看好多研报和财报,信息太分散了。
能不能做一个工具,把这些文档都放进去,然后可以搜索和问答?brainstorming 来自 superpowers 体系,基于 description 字段的语义匹配触发——当 Claude Code 检测到需求探索类请求时自动激活。如果想确保触发,可以在提示词中提及任务性质,或直接用 /brainstorming 手动调用。它不会立刻给出技术方案,而是先进入提问环节。
brainstorming 的追问机制
brainstorming 通过逐个提问来补全需求中的模糊地带。每次只问一个问题,等用户回答后再提下一个。典型的追问包括:
- 文档主要是什么格式?PDF、Excel、还是网页?大概有多少份?
- 谁在用这个工具?只有你们部门,还是要给其他团队用?
- 搜索时希望看到原文片段,还是 AI 帮你总结一段回答?
- 有没有权限要求?比如某些研报只能特定人看?
每个问题背后都对应一个架构决策。用户不需要理解技术细节,只需要回答业务层面的判断。
brainstorming 内置了一条硬约束:设计文档未经用户批准之前,Claude Code 不会写任何代码——不建目录、不创建文件、不生成骨架。这条规则写在 Skill 定义中,Claude Code 自动遵守。金融系统对数据准确性要求严格,一个错误的架构假设可能导致后期大规模返工。
追问过程中,有三个决策对系统架构影响最大:
| 决策点 | 用户选择 | 架构影响 |
|---|---|---|
| 数据源优先级 | 先支持 PDF 研报,后续扩展 Excel 和 RSS | 首版只需实现 PDF 解析,降低复杂度 |
| 检索粒度 | 返回原文片段,附带来源标注 | 只需语义检索,无需 RAG 管线 |
| 权限安全 | 暂不区分角色,全员可见 | 首版不需要权限模块 |
这些选择帮助 brainstorming 收窄方案范围。用户做完决策后,Skill 提出 2-3 种可行方案供选择,附带取舍分析和推荐。
产出:设计文档
用户逐节确认方案后,brainstorming 将所有讨论结果汇总为一份设计文档,保存到 docs/superpowers/specs/ 目录并用 git commit 提交。这份 spec 是整条文档链的起点——下一阶段的 writing-plans 会读取它来生成实施计划。文档涵盖问题定义、核心功能模块、技术选型和分阶段实施路线。
docs/superpowers/specs/2026-05-05-findata-kb-design.md
# 金融多源知识库查询系统 — 设计文档
状态:待审批
## 问题定义
分析师需要从大量 PDF 研报和 Excel 财报中快速定位信息。
当前依赖手动搜索,效率低、覆盖面窄。
## 核心功能模块
- 文档导入引擎(PDF 解析 + 元数据提取)
- 语义检索服务(ChromaDB + Ollama 本地嵌入)
- Web 查询界面(Next.js + shadcn/ui)
## 分阶段实施
- Phase 1:PDF 导入 + 语义检索 + Web 界面
- Phase 2:Excel 支持 + 元数据筛选
- Phase 3:RSS 新闻 + RAG 问答这份文档不是一次生成的。brainstorming 在每个提问、方案选择、分节确认环节都在逐步完善内容。
一个常见错误是在提需求时直接指定技术栈——“用 Python + FastAPI + PostgreSQL 做一个知识库”。这会跳过 brainstorming 的需求澄清环节,让 Claude Code 直接进入实现。结果往往是:技术选型没问题,但需求理解有偏差,做出来的东西不是用户真正想要的。把技术选型交给 brainstorming,用户只负责回答业务问题。