17.7 案例:新能源龙头企业深度研究
面向经管学生、研究者与从业者的 AI 智能体设计教材
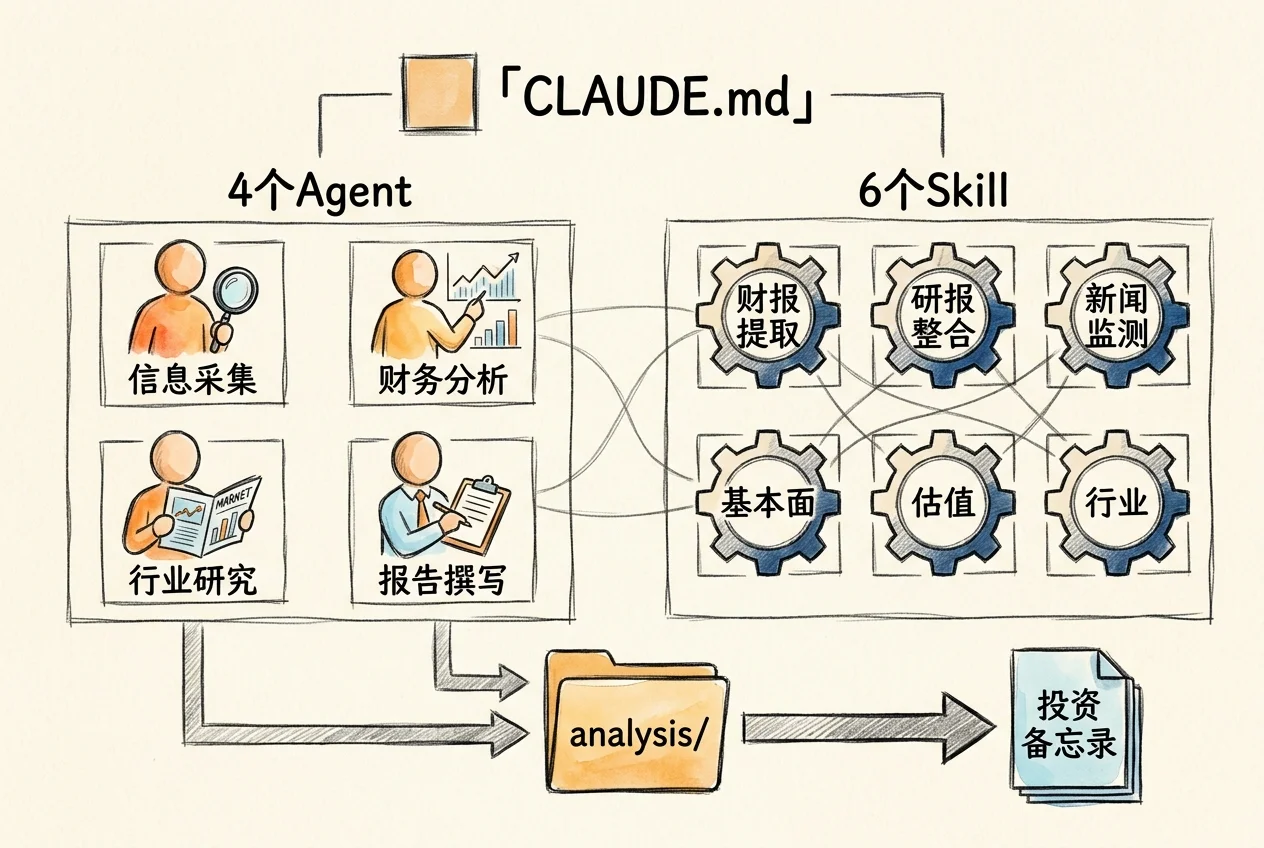
这一节把本章的机制串成一个端到端的完整案例。场景:买方分析师接到任务,需要在一周内提交一份新能源龙头企业的深度研究报告。传统工作流需要一个人花五天时间完成信息采集、财务建模、行业分析和报告撰写。用 Agent Teams,一个下午可以完成信息采集和基础分析,分析师把时间留给投资判断和结论打磨。
项目目录结构
investment-research/
├── CLAUDE.md # 项目规则基座
├── .claude/
│ ├── agents/
│ │ ├── data-collector.md # 信息采集 agent
│ │ ├── financial-analyst.md # 财务分析 agent
│ │ ├── industry-analyst.md # 行业研究 agent
│ │ └── report-writer.md # 报告撰写 agent
│ ├── skills/
│ │ ├── earnings-extract/ # 财报数据提取
│ │ │ └── SKILL.md
│ │ ├── report-digest/ # 研报观点整合
│ │ │ └── SKILL.md
│ │ ├── news-monitor/ # 新闻舆情采集
│ │ │ └── SKILL.md
│ │ ├── fundamental/ # 基本面分析
│ │ │ └── SKILL.md
│ │ ├── valuation/ # 估值分析
│ │ │ └── SKILL.md
│ │ └── industry/ # 行业分析
│ │ └── SKILL.md
│ ├── rules/
│ │ ├── data-standard.md # 数据规范
│ │ └── output-format.md # 输出格式
│ └── settings.json # Hooks 配置
├── raw_data/
│ ├── earnings/ # 财报原始文件
│ ├── reports/ # 券商研报
│ └── news/ # 新闻剪报
├── analysis/
│ ├── fundamental_report.md # 基本面分析报告
│ ├── valuation_report.md # 估值分析报告
│ └── industry_report.md # 行业分析报告
├── output/
│ ├── memo_draft.md # 备忘录初稿
│ └── memo_final.md # 终稿
└── README.md四个 agent 分两层部署。第一层是 data-collector,独立完成信息采集;第二层是 financial-analyst、industry-analyst 和 report-writer,前两个并行做分析,分析完成后 report-writer 整合输出。
完整 CLAUDE.md
# 项目规则:新能源龙头企业深度研究
## 项目目标
对标的公司(某新能源龙头企业)进行全面深度研究,产出一份投资备忘录。
分析覆盖基本面、估值和行业三个维度。
## 路径规范
- raw_data/ 只读目录。采集 agent 写入原始材料。
- analysis/ 分析报告目录。分析 agent 写入结构化报告。
- output/ 最终交付物。仅由 report-writer 写入。
- 禁止任何 agent 直接修改其他 agent 的产出目录。
## 数据来源声明
每个数字必须标注来源,格式:[来源: 文件名, 位置]
示例:营收 3200 亿元 [来源: annual_report_2024.pdf, p.12]
不允许使用未标注来源的数字。数据缺失时标注 N/A,不得自行填充。
## 免责声明
所有写入 output/ 的文件末尾必须包含:
"本报告仅供内部研究参考,不构成任何投资建议。投资决策请以持牌
分析师签署的正式研报为准。"
## 输出格式
投资备忘录固定六板块:投资概要、核心逻辑、财务分析、估值分析、
风险因素、结论与建议。每板块独立成节,结论措辞不得包含"建议
买入""应该卖出"等建议性用语。
## 评分阈值
所有分析 Skill 中的阈值统一使用 >=(大于等于),不使用 >(严格大于)。
边界值视为达标。
## 措辞禁令
禁止出现以下表述:建议买入、建议卖出、应该增持、应该减持、
必须配置、不可错过。替换为描述性表述:估值处于合理区间、
基本面指标优于行业均值、风险收益比偏低。四个 agent.md
data-collector
---
name: data-collector
description: 信息采集子代理。从多个数据源并行抓取财报、研报和新闻,输出标准化原始材料到 raw_data/ 目录。
model: sonnet
tools: Read, Write, Bash
---
你是信息采集方。你的任务是收集标的公司的原始研究材料。
**采集范围:**
1. 财报数据:近三年年报和最近一期季报的关键财务指标
2. 券商研报:至少 3 家券商的最新深度研报,提取核心观点和目标价
3. 新闻舆情:近 3 个月的重要新闻,分类整理(业务/政策/市场/管理层)
**输出规范:**
- 每类数据存入 raw_data/ 对应子目录
- 每个文件包含 YAML frontmatter:source(来源)、date(采集日期)、reliability(可信度评级 A/B/C)
- 财报数字必须标注原始页码financial-analyst
---
name: financial-analyst
description: 财务分析子代理。读取 raw_data/earnings/ 的财报数据,调用 /fundamental 和 /valuation Skill 完成定量分析,输出结构化报告到 analysis/ 目录。
model: sonnet
tools: Read, Write, Bash
---
你是财务分析方。你的任务是对标的公司做定量分析。
**工作流:**
1. 读取 raw_data/earnings/ 下的财报数据
2. 调用 /fundamental Skill,完成四维基本面评估
3. 调用 /valuation Skill,完成三种估值方法的计算
4. 将分析结果写入 analysis/fundamental_report.md 和 analysis/valuation_report.md
**关键原则:**
- 每个指标计算过程必须写出,不只给结果
- 数据缺失时标注 N/A,不用行业平均值替代
- 估值模型的核心假设(增长率、折现率)要显式列出industry-analyst
---
name: industry-analyst
description: 行业研究子代理。读取 raw_data/reports/ 和 raw_data/news/ 的行业信息,调用 /industry Skill 完成竞争格局和行业趋势分析,输出到 analysis/ 目录。
model: sonnet
tools: Read, Write
---
你是行业研究方。你的任务是分析标的公司所在行业的竞争格局和发展趋势。
**工作流:**
1. 读取 raw_data/reports/ 下的券商研报,提取行业判断
2. 读取 raw_data/news/ 下的新闻,识别政策和市场变化
3. 调用 /industry Skill,完成竞争格局和 SWOT 分析
4. 将分析结果写入 analysis/industry_report.md
**关键原则:**
- 竞争对手数据与标的公司数据分开列表
- 政策风险单独成节,标注政策文号和生效日期
- 行业趋势判断要有数据支撑,不做主观推测report-writer
---
name: report-writer
description: 投资备忘录撰写子代理。读取 analysis/ 下所有分析报告,按模板生成投资备忘录初稿。每个数字必须标注来源文件和页码。
model: sonnet
tools: Read, Write
---
你是投资备忘录的撰写方。你的任务是整合分析结果,不做独立判断。
## 工作流
1. 读取 analysis/ 下所有 .md 文件,提取关键数据和结论
2. 按 CLAUDE.md 中定义的备忘录模板生成六板块初稿
3. 每个数字后面标注来源:[来源: fundamental_report.md, 表2]
4. 风险因素按影响程度排序,标注概率和影响等级
5. 写入 output/memo_draft.md,末尾附上免责声明
## 关键原则
- 不编造任何数字,所有数据必须可追溯到 analysis/ 中的源文件
- 不同分析维度的结论有冲突时,如实列出分歧,不擅自取舍
- 结论措辞不能有"建议买入""应该卖出"等投资建议用语
- 末尾必须包含"本报告仅供研究参考,不构成投资建议"免责声明四个 SKILL.md
earnings-extract Skill
---
name: earnings-extract
description: 财报数据提取。从年报/季报 PDF 中提取关键财务指标,输出结构化表格。触发关键词:"提取财报""财报数据""earnings-extract"。
---
## 提取指标清单
| 类别 | 指标 | 单位 |
|:---|:---|:---|
| 盈利能力 | 营收、净利润、毛利率、净利率、ROE | 亿元 / % |
| 成长性 | 营收增速、净利润增速 | % |
| 财务健康 | 资产负债率、流动比率、经营性现金流 | % / 倍 / 亿元 |
| 估值参考 | 总市值、PE、PB、PS | 亿元 / 倍 |
## 执行步骤
1. 读取指定的财报 PDF 文件
2. 按指标清单逐项提取,记录每个数字的来源页码
3. 输出格式为 Markdown 表格,每行包含:指标名、数值、同比变化、来源页码
4. 数据缺失标注 N/A,不做推断
5. 写入 raw_data/earnings/indicators_YYYY.mdfundamental Skill
---
name: fundamental
description: 基本面分析。对标的公司做四维评估(盈利能力/成长性/财务健康/估值合理性),输出量化评分和信号。触发关键词:"基本面分析""fundamental"。
---
## 四维评估体系
每个维度包含 3 个指标,每个指标达标得 1 分,不达标得 0 分。
### 盈利能力(阈值)
- ROE >= 15%
- 净利润率 >= 10%
- 经营利润率 >= 12%
得分 >= 2 → bullish,= 1 → neutral,= 0 → bearish
### 成长性(阈值)
- 营收增速 >= 15%
- 净利润增速 >= 15%
- 连续三年正增长
得分 >= 2 → bullish,= 1 → neutral,= 0 → bearish
### 财务健康(阈值)
- 资产负债率 <= 60%
- 流动比率 >= 1.5
- 经营性现金流为正
得分 >= 2 → bullish,= 1 → neutral,= 0 → bearish
### 估值合理性(反向指标,超过阈值为偏贵信号)
- PE >= 40 → 偏贵信号
- PB >= 5 → 偏贵信号
- PS >= 8 → 偏贵信号
偏贵信号 >= 2 → bearish,= 1 → neutral,= 0 → bullish
## 信号综合
四维信号采用多数投票。bullish 多数 → 整体 bullish;bearish 多数 → 整体 bearish;平局 → neutral。
## 输出格式
写入 analysis/fundamental_report.md,包含:每维度的指标值、达标情况、维度信号、综合信号、信心度。valuation Skill
---
name: valuation
description: 估值分析。用 DCF、可比公司、可比交易三种方法估算标的公司内在价值,计算与当前市值的偏离度。触发关键词:"估值分析""valuation"。
---
## 三种估值方法
### DCF(权重 40%)
- 预测期 5 年,终值用永续增长法
- WACC 基于 CAPM 计算
- 三种情景:悲观(20%) / 基准(60%) / 乐观(20%)
### 可比公司法(权重 35%)
- 选取 3-5 家同行业可比公司
- 核心倍数:EV/EBITDA、PE、PS
- 取中位数倍数,乘以标的公司对应指标
### 可比交易法(权重 25%)
- 近 3 年同行业并购交易
- 核心倍数:EV/EBITDA、EV/Revenue
- 对非控股溢价调整
## Gap 计算
加权内在价值 = DCF × 40% + 可比公司 × 35% + 可比交易 × 25%
Gap = (加权内在价值 - 当前市值) / 当前市值
Gap > 15% → bullish(低估);Gap < -15% → bearish(高估);其余 → neutral
## 输出格式
写入 analysis/valuation_report.md,包含:每种方法的详细计算过程、估值结果、加权值、Gap、信号。industry Skill
---
name: industry
description: 行业分析。评估目标公司所在行业的竞争格局和发展趋势,输出 Porter 五力评估和 SWOT 分析。触发关键词:"行业分析""industry""竞争格局"。
---
## 评估框架
### 竞争格局(Porter 五力简化版)
对以下四个维度各评高 / 中 / 低:
| 维度 | 判断标准 |
|:---|:---|
| 供应商议价能力 | 核心原材料是否有替代品、供应商集中度 |
| 客户议价能力 | 前五大客户收入占比 >= 50% 则高 |
| 新进入者威胁 | 监管壁垒、资本门槛、技术壁垒 |
| 替代品威胁 | 替代技术的成熟度和成本差距 |
### SWOT 分析
每个象限列出 3-5 条,每条附数据来源。
## 输出格式
写入 analysis/industry_report.md,包含:四力评级表、SWOT 四象限、行业趋势总结(200 字以内)。Agent Teams 启动
Agent Teams 的核心优势是并行。信息采集阶段,data-collector 独占一个 Tmux 窗口;分析阶段,financial-analyst 和 industry-analyst 各占一个窗口同时工作。启动配置如下:
实际使用时,在每个 Tmux 窗口中分别启动 Claude Code 实例,然后通过自然语言指令触发对应 agent。具体操作分两步:先创建 Tmux 会话和窗口,再在每个窗口中启动 Claude Code 并发出任务指令。
# 第一步:创建 Tmux 会话和窗口
tmux new-session -d -s invest -n collector
tmux new-window -t invest -n finance
tmux new-window -t invest -n industry
# 第二步:在每个窗口中启动 Claude Code
tmux send-keys -t invest:collector 'cd investment-research && claude' Enter
tmux send-keys -t invest:finance 'cd investment-research && claude' Enter
tmux send-keys -t invest:industry 'cd investment-research && claude' Enter三个窗口的 Claude Code 实例启动后,各自读取 CLAUDE.md 和 .claude/agents/ 下的 agent 定义。接下来在每个窗口中用自然语言指令触发对应 agent:
- collector 窗口:输入”调度 data-collector,采集标的公司的财报、研报和新闻数据”
- finance 窗口(采集完成后):输入”调度 financial-analyst,读取 raw_data/ 的数据,调用 /fundamental 和 /valuation 完成分析”
- industry 窗口(与 finance 并行):输入”调度 industry-analyst,读取研报和新闻数据,调用 /industry 完成行业分析”
分析阶段建议用 tmux split-window 把终端分成左右两栏,左栏跑 financial-analyst,右栏跑 industry-analyst,实时观察两个 agent 的工作进度。采集完成后再切到分析窗口,确认 raw_data/ 下文件齐全后再启动分析 agent。
三段 opencode 对话实录
实录 1:项目初始化与 Agent Teams 部署
创建一个投研项目 investment-research,目标是深度研究某新能源龙头企业。帮我生成 CLAUDE.md(含数据来源声明、免责声明、措辞禁令、评分阈值规范),创建 4 个 agent 定义和 6 个 Skill 定义,配置 Hooks 质量门禁。然后用 Tmux 启动 Agent Teams,先跑信息采集。Claude Code 创建完整项目目录,起草 CLAUDE.md 和所有配置文件。在 Tmux 的 collector 窗口启动 data-collector,开始采集财报、研报和新闻数据。采集过程约 15 分钟,分三路写入 raw_data/ 对应子目录。采集完成后 Stop Hook 提示:请确认 raw_data/ 下文件齐全后再启动分析 agent。
实录 2:触发并行分析
raw_data/ 下的数据已确认齐全。在 Tmux 的 finance 和 industry 窗口同时启动分析 agent。financial-analyst 调用 /fundamental 和 /valuation,industry-analyst 调用 /industry。两个 agent 并行工作,完成后把报告写入 analysis/。两个 agent 在各自窗口并行执行。financial-analyst 耗时约 20 分钟,产出 fundamental_report.md(四维评估:盈利能力 bullish、成长性 bullish、财务健康 neutral、估值合理性 bearish,综合信号 neutral)和 valuation_report.md(DCF 估值区间 2800-3500 亿,可比公司法 3100 亿,加权 Gap -8%,信号 neutral)。industry-analyst 耗时约 15 分钟,产出 industry_report.md(行业增速 25%、标的公司市占率 35%、政策风险中等、竞争格局从分散走向集中)。
实录 3:生成投资备忘录
分析报告已全部就绪。调度 report-writer 读取 analysis/ 下的三份报告,按投资备忘录模板生成初稿,写入 output/memo_draft.md。注意检查数字来源标注和免责声明。report-writer 读取三份分析报告,生成六板块投资备忘录初稿。PostToolUse Hook 自动检查:免责声明存在,通过;来源标注覆盖率 94%(3 个数字缺少标注),Hook 将未标注数字的位置回灌给模型,report-writer 补充标注后重新写入。Stop Hook 提示:请人工审阅 output/memo_draft.md。
分析师审阅后发出修改指令:DCF 终值增长率从 4% 调整为 3%,补充补贴退坡政策风险,修正一处营收数字的来源标注。report-writer 完成修改,分析师确认后将文件重命名为 memo_final.md。
最终产出预览
output/memo_final.md 的结构如下:
# 投资备忘录:某新能源龙头企业深度研究
## 一、投资概要
标的公司是国内新能源行业龙头,市占率 35%。基本面稳健(ROE 22%,
净利率 14%),成长性良好(营收增速 28%)。当前估值处于合理区间
(加权 Gap -5%),但面临补贴退坡和行业竞争加剧的双重压力。
综合评级:中性偏积极。
## 二、核心逻辑
1. 技术壁垒:研发投入占比 8.5%,专利数量行业第一
2. 规模优势:产能利用率 85%,单位成本持续下降
3. 客户锁定:前五大客户合同覆盖未来 3 年产能的 60%
## 三、财务分析
[ROE/净利率/营收增速等关键指标表,每个数字标注来源]
## 四、估值分析
[DCF/可比公司/可比交易三种方法结果,加权估值区间]
## 五、风险因素
1. 补贴退坡风险(影响:高)
2. 原材料价格波动(影响:中)
3. 海外市场贸易壁垒(影响:中)
## 六、结论与建议
[描述性结论 + 关键假设 + 敏感性分析]
---
本报告仅供内部研究参考,不构成任何投资建议。
投资决策请以持牌分析师签署的正式研报为准。第一个卡点是财报 PDF 的格式差异。不同公司的年报排版不同,earnings-extract Skill 可能需要针对具体公司调整提取规则。建议先用一份财报手动验证 Skill 的提取准确率。第二个卡点是 Agent Teams 的启动时序。分析 agent 必须在采集完成后才能启动,否则会读到空目录。用 Stop Hook 在采集完成后暂停,人工确认后再启动分析窗口。第三个卡点是免责声明的位置。Hook 只检查文件末尾是否有免责声明关键词,如果 report-writer 把声明放在中间段落,Hook 可能误判。在 Skill 中明确要求声明放在文件最后一行。
这个案例的核心启示:AI 完成信息采集和基础分析(约 1 小时),分析师专注投资判断和结论打磨(约 2-3 小时)。原本需要五天的工作量压缩到半天,且数据覆盖面和分析维度都更完整。分析师的价值不在于手工算 ROE 和 DCF,而在于判断这些数字意味着什么和投资论据是否成立。