引用的准确性是学术写作的底线。一条错误的引用——作者名拼错、年份写错、甚至引用了一篇不存在的论文——足以损害整篇综述的可信度。这一节介绍如何用 /citation-management Skill 和 Zotero MCP 系统化地管理引用。
Zotero MCP BibTeX 导出(替代路径)
如果论文已在 Zotero 库中,可以直接用 MCP 导出 BibTeX:
导出 Zotero 中 item key 为 B4EZFZWP 的文献元数据为 BibTeX 格式,
保存到 citations/references.bib
两条路径的选择:Zotero 库中已有的论文用 MCP 导出更快;新发现但尚未入库的论文用 /citation-management 从 DOI 提取。
字段验证:validate_citations.py
validate_citations.py 检查 BibTeX 条目的完整性,检测三类问题:
| 必填字段缺失 |
缺少作者或标题 |
错误 |
| 推荐字段缺失 |
缺少 DOI 或卷号 |
警告 |
| 重复条目 |
同一篇论文出现两次 |
错误 |
检测结果输出为 JSON 报告,便于批量处理。
validate_citations.py 有两个已知问题需要注意:
--check-dois 功能存在误报——有效 DOI 可能被判定为无法解析。建议只使用基础字段验证,不加 --check-dois 参数。--auto-fix 参数当前不可用。发现问题后需要根据验证报告手动修复。
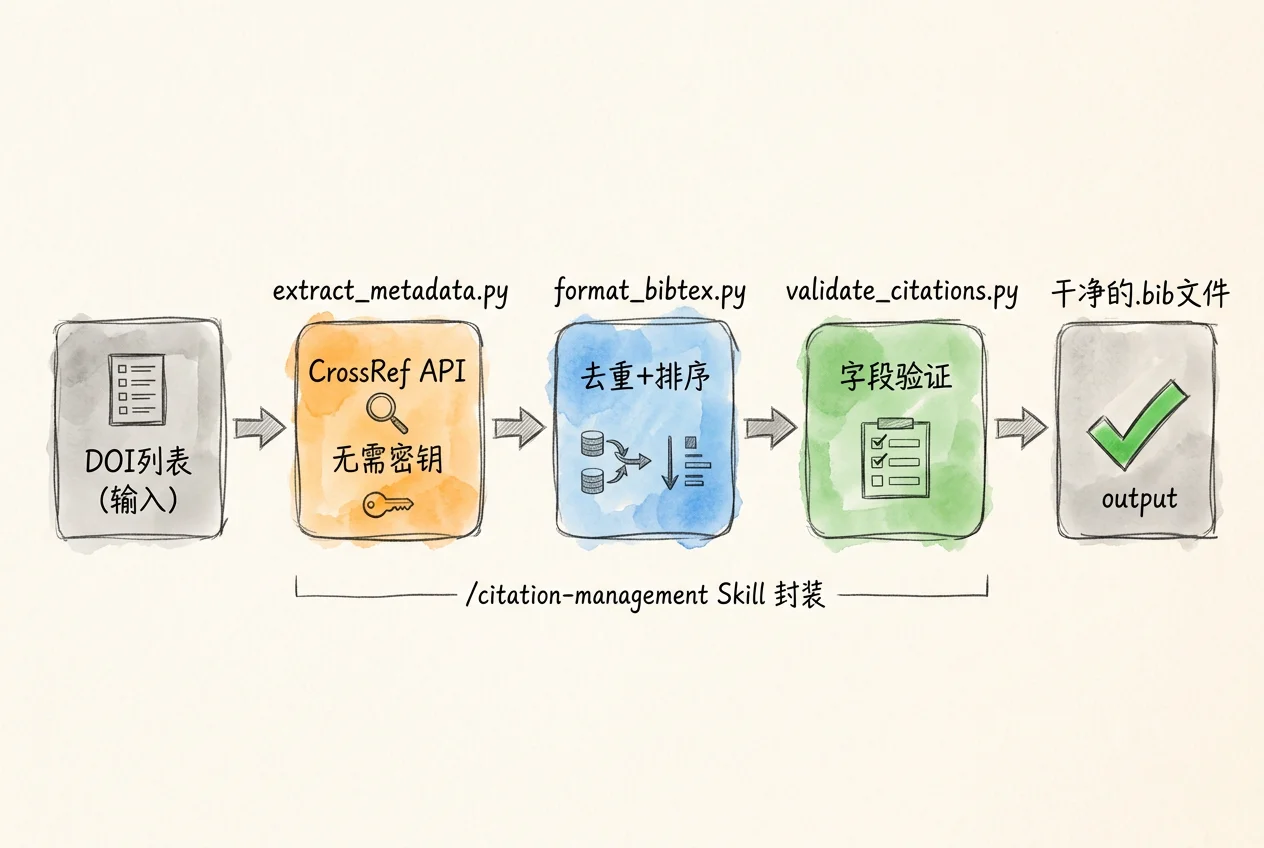
引用管理的完整流程
将上述工具串联,形成一条引用管理流水线:
flowchart LR
A["DOI 列表<br/>(从摘要表提取)"] --> B["extract_metadata.py<br/>提取 BibTeX"]
B --> C["format_bibtex.py<br/>去重 + 排序"]
C --> D["validate_citations.py<br/>字段验证"]
D --> E["干净的 .bib 文件<br/>(可用于 LaTeX)"]
flowchart LR
A["DOI 列表<br/>(从摘要表提取)"] --> B["extract_metadata.py<br/>提取 BibTeX"]
B --> C["format_bibtex.py<br/>去重 + 排序"]
C --> D["validate_citations.py<br/>字段验证"]
D --> E["干净的 .bib 文件<br/>(可用于 LaTeX)"]
/citation-management Skill 将上述三个脚本封装为一条指令。调用时,Skill 根据提示词中描述的任务目标自动选择并依次执行相应脚本,读者只需描述想要的结果:
用 /citation-management 处理引用管理流水线:
1. 从 literature_notes/summary_table.md 中提取所有论文的 DOI,保存为 citations/doi_list.txt
2. 用 extract_metadata.py 从 DOI 列表批量提取 BibTeX,输出到 citations/raw.bib
3. 用 format_bibtex.py 对 citations/raw.bib 去重排序,输出到 citations/references.bib
4. 用 validate_citations.py 验证 citations/references.bib,生成报告到 citations/validation.json
列出验证报告中发现的问题。