18.3 文献阅读与信息提取
面向经管学生、研究者与从业者的 AI 智能体设计教材
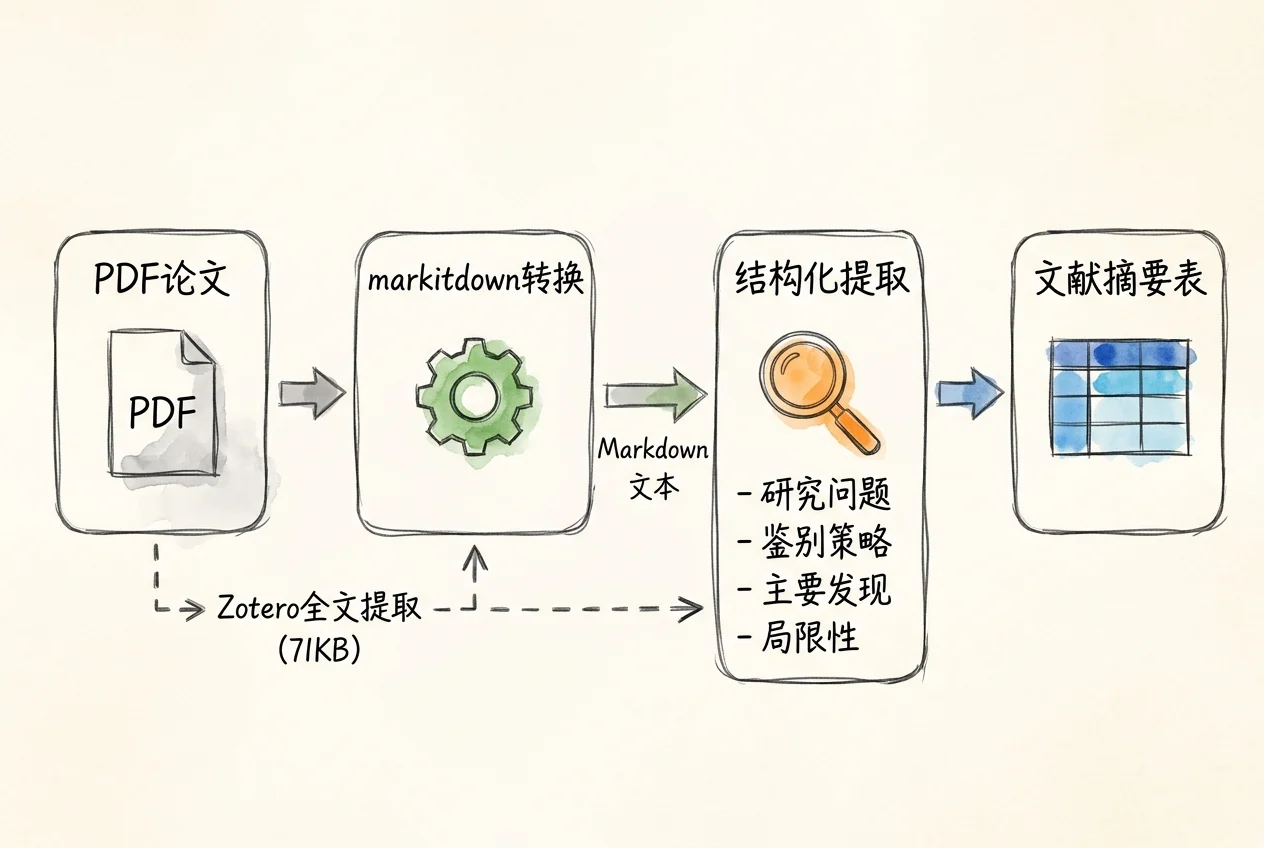
要写综述,需要从每篇论文中提取研究问题、方法、数据来源、主要发现和局限性。这个过程的本质是把非结构化的论文文本转化为结构化的信息表。
markitdown:PDF 转 Markdown
markitdown 是 Microsoft 开发的 Python 工具(已测试版本 v0.1.3),将 PDF、Word、Excel 等多种格式统一转换为 Markdown。它是文献摄入层的首选工具——一个接口处理所有格式,输出对 AI 友好的文本。实测中,它成功转换了 19 页中文 PDF,输出 22768 字符,编码无乱码,标题层级保留良好。
K-Dense Scientific Skills 中包含 /markitdown Skill,可以直接在 Claude Code 中调用,无需手写 Python 代码。Skill 文件负责调用策略,markitdown Python 库(下方安装)是实际执行转换的运行时依赖,两者缺一不可。
用 /markitdown 将 papers/Tversky_Kahneman_1991_Loss_Aversion.pdf 转换为 Markdown,
保存到 extracts/ 目录批量转换多篇论文:
用 /markitdown 批量转换 papers/ 目录下的所有 PDF 为 Markdown,
输出到 extracts/ 目录,保持原文件名安装依赖
pip install 'markitdown[all]'[all] 选项一次安装全部格式支持(PDF、Word、Excel、图片 OCR 等)。核心依赖只有 markitdown 本身,无需额外配置。
如需更精细的控制(如按文件名筛选、指定编码),可以通过指令让 Claude Code 编写并执行自定义转换脚本:
在 papers/ 目录中,只转换文件名包含 2020-2024 的 PDF 为 Markdown,
输出到 extracts/ 目录,用 markitdown 库执行,保留原文件名markitdown 对复杂表格的提取不如 pdfplumber 精准。如果论文中有重要的回归结果表格需要精确的行列结构,可以让 Claude Code 调用 pdfplumber 提取:
用 pdfplumber 提取 extracts/Odean_1998.pdf 中所有表格,
输出为 Markdown 表格格式,保存到 extracts/Odean_1998_tables.md对大多数文献综述场景,markitdown 的输出质量已经足够。pdfplumber 在精确表格提取和 PDF 元数据读取方面更强。
Zotero MCP 全文提取(替代路径)
如果论文已在 Zotero 库中且完成了全文索引,可以直接用 zotero_get_item_fulltext 获取全文文本,无需本地 PDF 文件:
获取 Zotero 中 item key 为 KIHH9U84 的论文全文实测中,这个工具返回了约 71KB 的完整论文文本,质量与 markitdown 转换结果相当。优势是不需要本地 PDF 文件,直接从 Zotero 的全文索引中提取。限制是论文必须已被 Zotero 索引——未索引的论文需要先在 Zotero 桌面端触发索引更新。
两条路径的选择:本地有 PDF 文件时用 markitdown(支持批量、速度快);PDF 文件在 Zotero 云端同步时用全文提取工具(无需下载)。
结构化信息提取
拿到论文的 Markdown 文本后,用提示词提取关键信息。以下是经济学论文版本的提取模板:
请从以下论文文本中提取结构化信息,按这个格式输出:
## 文献摘要卡片
- **标题**:
- **作者**:
- **年份**:
- **期刊**:
- **研究问题**:用一句话概括
- **理论框架**:所依据的经济学理论
- **识别策略**:使用的因果推断方法(如 IV、DID、RDD、RCT)
- **数据来源**:数据集名称、样本量、时间跨度
- **主要发现**:列出 2-3 条核心结论
- **局限性**:作者自述或你判断的主要局限
- **与我的研究的关联**:这篇论文对本综述研究问题的贡献
---
论文文本:
[粘贴 markitdown 转换后的文本]这个模板中,识别策略和数据来源两个字段对经济学综述尤为重要。识别策略决定了论文在综述中的证据权重,数据来源帮助判断结论的可推广性。
AI 在提取研究方法和主要发现时可能出现偏差:识别策略可能被误判(如把 OLS 说成 IV)、数字和百分比可能被读错、论文的贡献可能被过度概括。关键数据务必回到原文核实。
构建文献摘要表
将多篇论文的提取结果汇总为一张表格,是文献综述写作的核心素材。按主题或方法分组,可以快速看出研究的共识、分歧和空白:
我已经提取了 15 篇论文的结构化信息(见 literature_notes/ 目录下的文件)。
请汇总为一张文献摘要表,包含以下列:作者、年份、研究问题、识别策略、样本、主要发现。
按主题分组:
(1) 损失厌恶的度量方法
(2) 对交易频率的影响
(3) 对资产配置的影响
保存到 literature_notes/summary_table.md。这张表就是综述写作的骨架。有了它,主题式综合就有了清晰的素材支撑。