21.3 安装与部署
面向经管学生、研究者与从业者的 AI 智能体设计教材
使用本地桌面应用或云端托管的读者可以跳过本节。本节重点介绍自建方案,自建的理由有二:
- 教学价值:只有自己装一遍,才能完整看清 OpenClaw 把模型、渠道、记忆、Hooks 这些组件如何串起来。微信接入、人格与记忆配置、调度 Opencode 协同,都需要这层认知。
- 灵活度与安全意识:自建版本可以装到任意机器上(云服务器、家里的小主机、个人电脑都行),这种灵活也意味着你需要清楚 OpenClaw 在机器上拥有读写文件、执行命令的权限。自己装一遍能直观感受它的能力边界和潜在风险,将来选择部署位置时心里有数。
推荐路径:先在云服务器上跑半个月,再迁回个人电脑
自建可以装在任意机器上,本书强烈推荐以一台 2 核 4G 起步的 Linux 云服务器作为上手起点。任意厂商均可,阿里云、腾讯云、火山引擎、华为云等都行。先在云服务器上跑半个月,把所有概念跑熟之后,再决定要不要把它迁到自己的笔记本或家里的小主机上。核心命令完全一样,迁移成本很低。
为什么先用云服务器?两条理由:
- 隔离与试错友好:OpenClaw 装好之后拥有读写本地文件、执行系统命令的权限。装在天天用的笔记本上,意味着 AI 跟个人照片、微信聊天记录、银行账单共处一台机器;装在云服务器上等于给 AI 圈了一个独立”工作间”。上手期难免乱配置、改坏环境,云服务器装坏了重置即可,私人资料完全不受影响。
- 24 小时常驻的天然条件:常驻智能体的核心价值是”机器始终开机”。云服务器是按月跑着的,关机的概率比每天合盖带回家的笔记本低得多。半个月体验下来,能完整感受到管家”任意时刻在线”的形态差异。
熟悉之后是否迁回个人电脑,按自己的工作习惯决定:如果日常办公就在那台 Mac 上、希望管家直接读取本地文档协助处理,那就迁回去;如果希望管家与私人数据完全隔离、长期托管在云端,那就留在云服务器上。
无论装在云服务器还是本地,都建议为 OpenClaw 单独申请一份模型 API Key,不要把日常给 Opencode 等其他工具用的 Key 复用过来,将影响范围控制在最小。
本节的安装演示,以”已经登录到一台 2 核 4G Linux 云服务器、获得 root 或 sudo 权限”为前提。
安装三步走
自建流程分三步:准备 Node 环境、下载 OpenClaw CLI、运行 onboard 完成安装与配置。
第一步:安装 Node 环境
OpenClaw 基于 Node.js 运行,推荐使用 Node 24,最低支持 Node 22.14+。低于最低要求的版本会在安装阶段直接报错。
macOS 与 Windows 读者请参照第 3 章的 Node.js 安装方式准备环境。Linux 云服务器推荐使用 nvm 安装。
- Node.js:运行 JavaScript 程序的基础环境,很多命令行工具都依赖它。
- nvm:Node Version Manager,Node 版本管理器,可以在同一台机器上并存多个 Node 版本并随时切换。
- npm:Node 自带的包管理器,用来下载和安装命令行工具。
在 Linux 云服务器终端依次执行以下命令:
# 下载并安装 nvm
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.4/install.sh | bash
# 加载 nvm(无需重启 shell)
\. "$HOME/.nvm/nvm.sh"
# 安装 Node 24
nvm install 24
# 验证 Node 版本
node -v # 应输出 v24.15.0 之类
# 验证 npm 版本
npm -v # 应输出 11.12.1 之类国内服务器直连 GitHub 常常很慢甚至失败,可以把 nvm 安装脚本换成 Gitee 镜像,并在安装 Node 前指定国内镜像源:
# 使用 Gitee 镜像安装 nvm
curl -o- https://gitee.com/mirrors/nvm/raw/v0.40.4/install.sh | bash
\. "$HOME/.nvm/nvm.sh"
# 指定 Node 下载镜像后再安装
export NVM_NODEJS_ORG_MIRROR=https://npmmirror.com/mirrors/node
nvm install 24
# 将 npm 源切换到国内镜像,后续 npm install 会走该源
npm config set registry https://registry.npmmirror.comnode -v 输出一个以 v 开头的版本号即表示 Node 已安装;满足最低要求即可进入下一步。
第二步:下载 OpenClaw
在同一个终端窗口执行以下命令,从 npm 官方仓库下载 OpenClaw 命令行工具并安装到全局环境:
npm install -g openclaw@latest参数 -g 表示全局安装,装好后在任意目录都能使用 openclaw 命令。下载完成后,通过版本号确认 CLI 安装成功:
openclaw --version正常输出版本号即说明 openclaw 可执行。此步只把命令本身放到全局环境,运行时所需的模型组件、技能、自动化钩子等部件将在下一步 onboard 引导中按需拉取。
第三步:运行 onboard 完成安装与配置
执行以下命令启动首次引导,同时把 OpenClaw 注册为系统后台服务:
openclaw onboard --install-daemon--install-daemon 参数指示 OpenClaw 在引导完成后将自身注册为开机自启的后台服务,系统启动时自动拉起,无需手动启动。
onboard 引导是 OpenClaw 首次运行时的交互式向导,用于一次性完成所有关键配置:选模型、填 API Key、启用 Hooks 等。引导完成后,系统就进入可用状态。
引导依次询问若干关键选项,按下文方式操作即可。
第 1-2 步:安全确认与配置模式
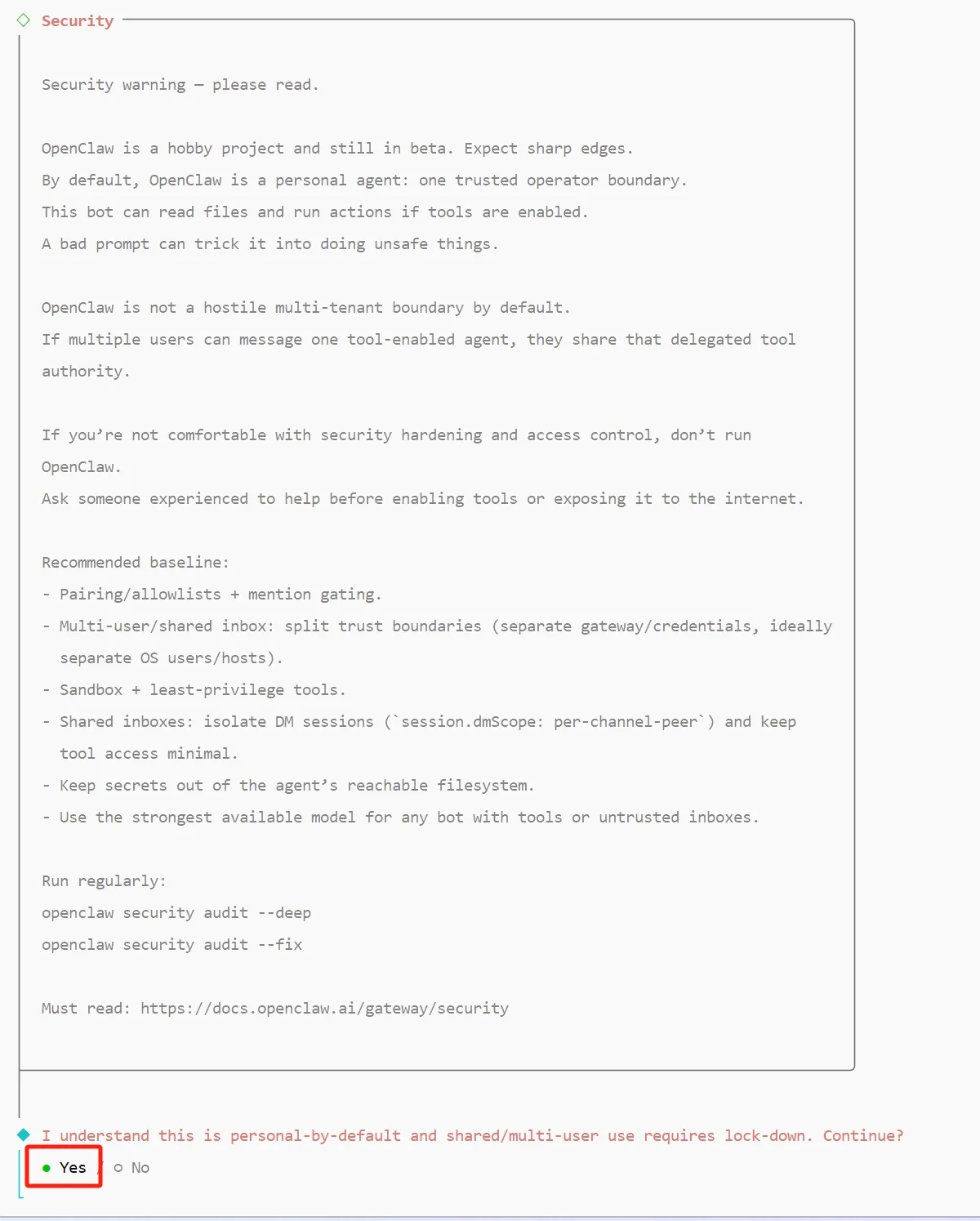
引导先显示一段安全声明,说明 OpenClaw 默认运行在个人单用户模式,会读写本地文件、执行系统命令;多人共享或对外暴露场景需要额外加固。阅读后选择 Yes 继续。
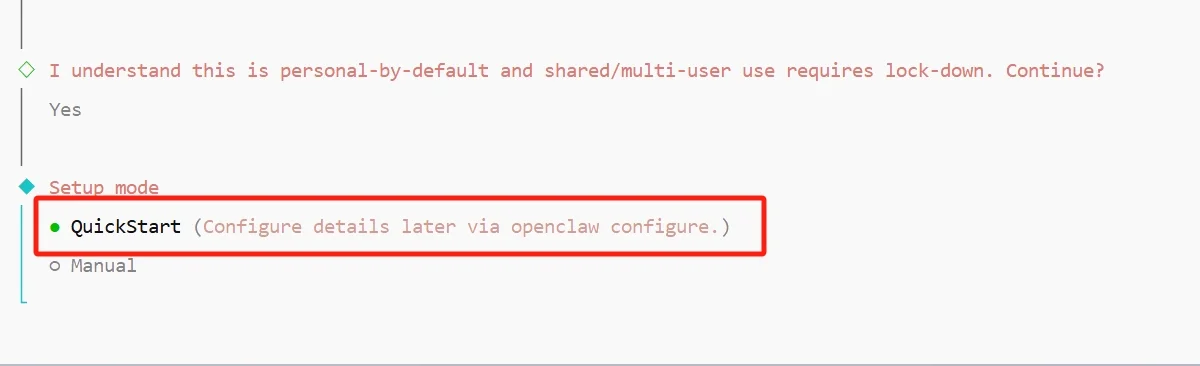
随后询问使用 QuickStart(快速开始)还是 Manual(手动配置)。建议首次安装选 QuickStart,该模式会为后续每步设定合理默认值,整个流程约两到三分钟。Manual 模式会把每个默认值都改为交互式追问,适合熟悉 OpenClaw 之后按需精细调整,首次安装不必使用。
第 3-5 步:模型提供商、认证方式与默认模型
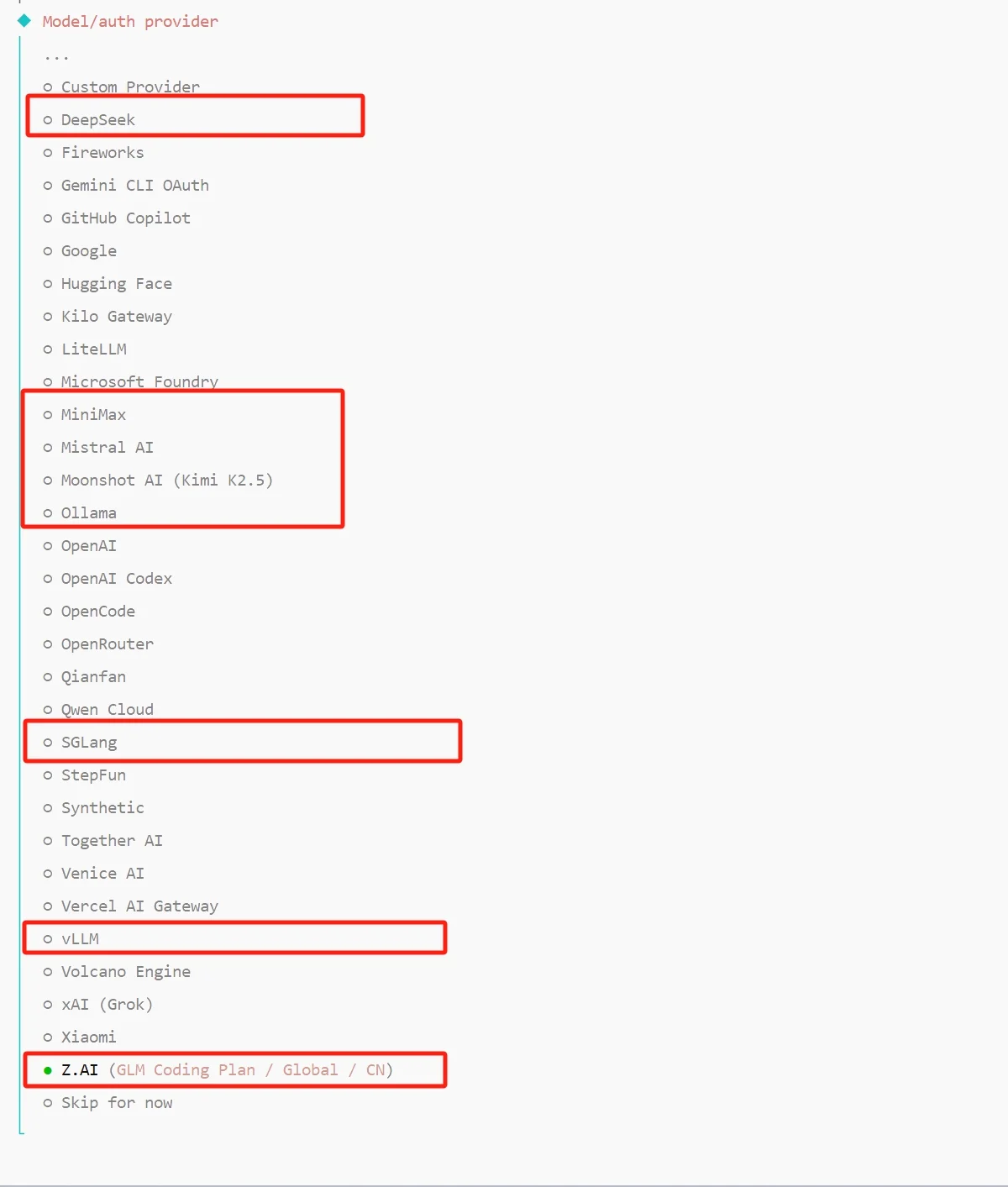
OpenClaw 支持的模型提供商按来源分为三类:
- 国内厂商:DeepSeek、Z.AI(智谱 GLM)、MiniMax、Moonshot AI(Kimi)、Volcano Engine(火山方舟)、Qianfan(百度千帆)、Qwen Cloud(通义千问)、Xiaomi、StepFun 等。
- 国际厂商:OpenAI、Anthropic、Google、Mistral、xAI 等。
- 自托管模型:Ollama、vLLM 等,适合已经在本地或自建服务器上跑模型的场景。
模型按自己已持有 API Key 或已部署好服务的厂商选择即可。下面以 Z.AI 为例说明。
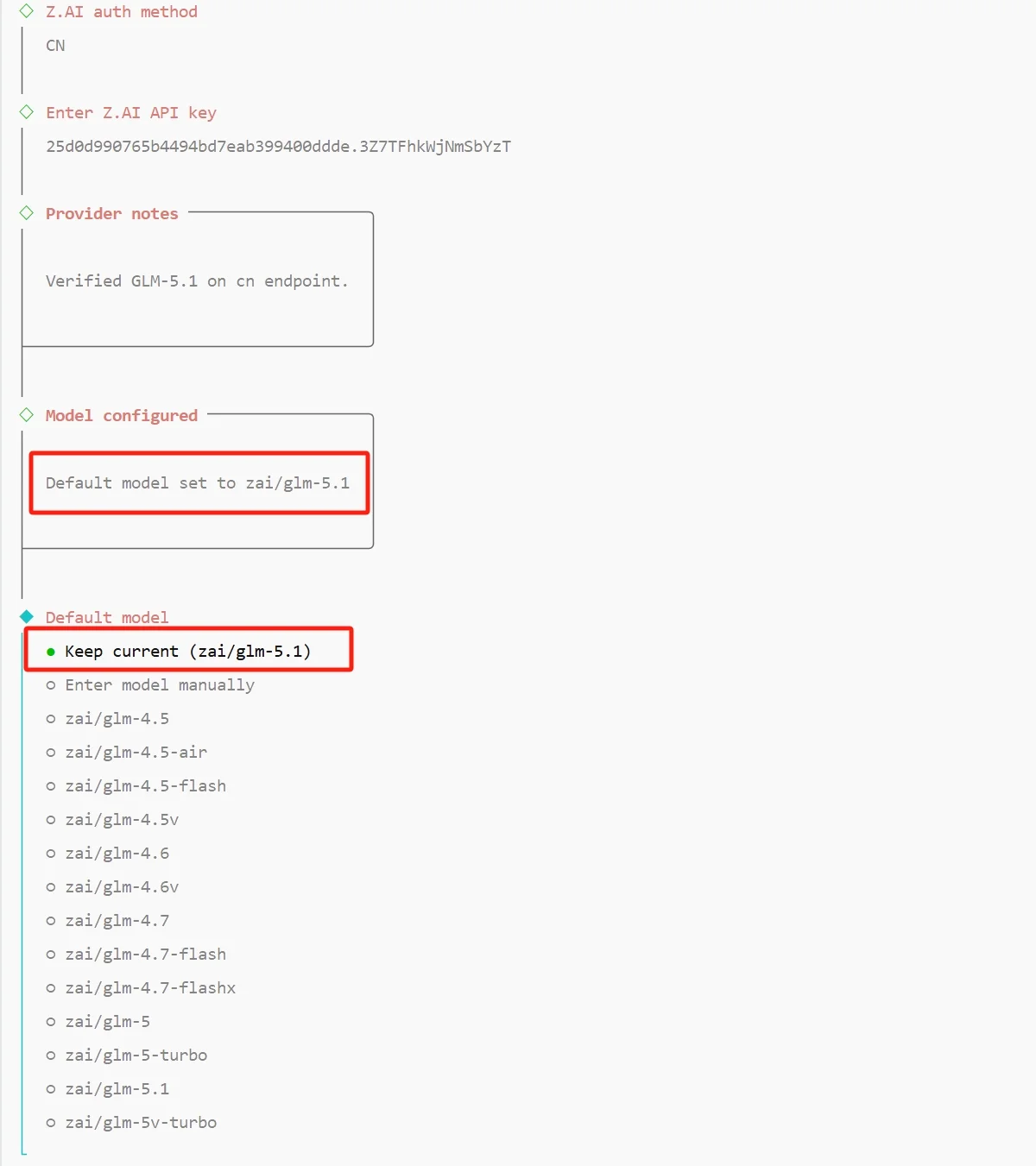
选定厂商后会显示该厂商下的认证方式选项。以 Z.AI 为例,可选 CN 直连、Coding-Plan-CN(GLM Coding Plan 国内版)、Coding-Plan-Global、Global,或直接粘贴 Z.AI API Key。选择当前账号下支持的方案即可。

将在对应平台注册获得的 API Key 粘贴至此处。引导流程会用该 Key 发起一次测试请求验证有效性,通过后自动将该套餐下的推荐模型设为默认模型,后续所有对话均使用该默认模型,除非在配置中另行指定。
第 6-7 步:消息渠道与搜索服务
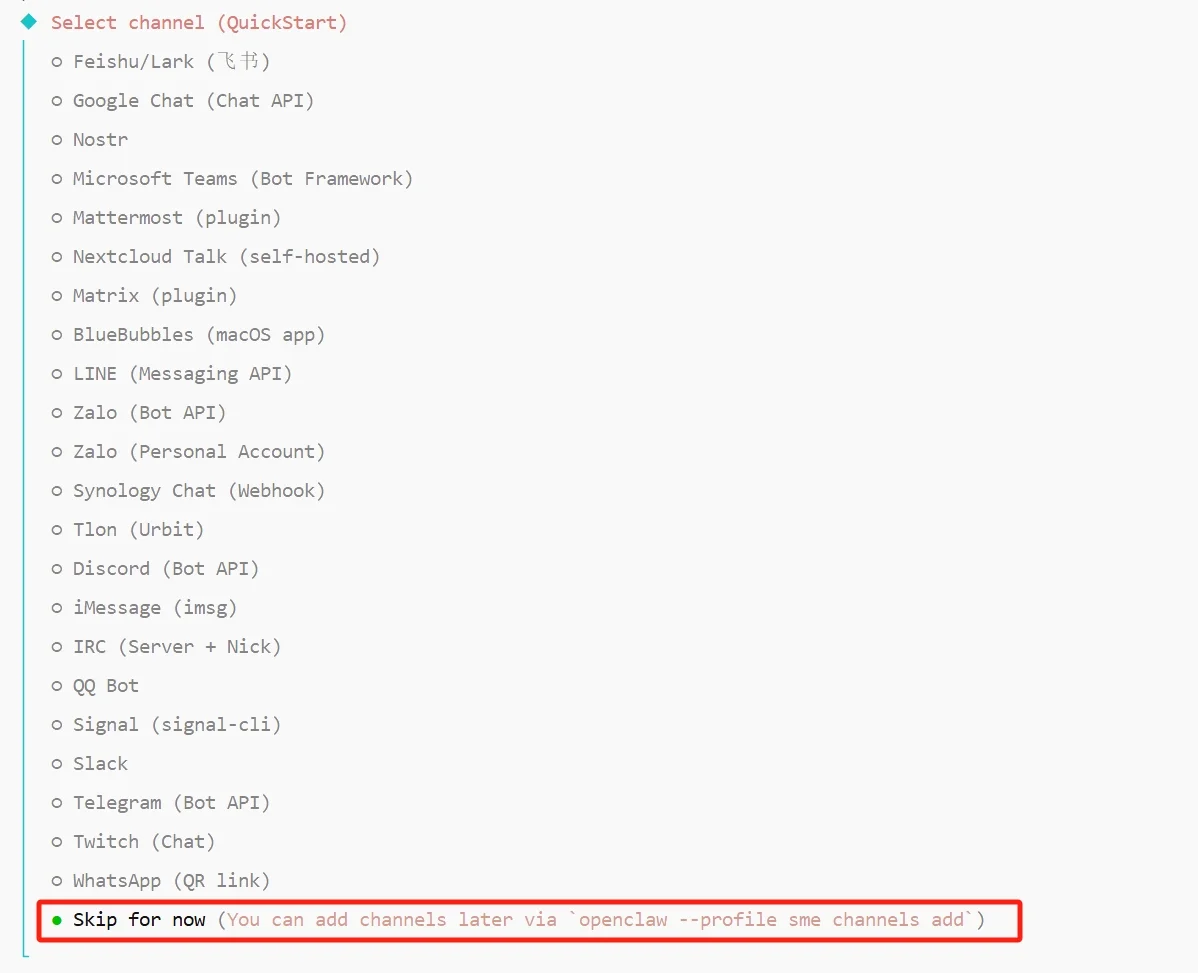
引导询问是否立即接入消息渠道,选项里覆盖 Feishu、Telegram、Slack、Discord、QQ Bot、WhatsApp、LINE 等二十余种平台(微信由独立插件接入,不在该列表中)。由于我们用微信,这里选 Skip for now(稍后跳过)即可。
下一步是联网搜索选择。管家处理许多请求需要联网搜索,此步用于选择搜索服务,首次安装可以直接跳过。个人使用推荐从 Tavily、Brave、Perplexity 等服务中挑一个申请 API Key 填入。OpenClaw 自由度很高,如果你习惯使用国产搜索 API,也可以先跳过本步,后续把 API Key 告诉管家,让它包装成一个工具并把配置存入记忆,联网搜索就会走这套自定义通道。
第 8-9 步:Skills 与 Hooks
引导汇总当前机器上 Skills 的可用情况,并询问是否立即配置。首次安装选 No 即可,暂时跳过技能配置。

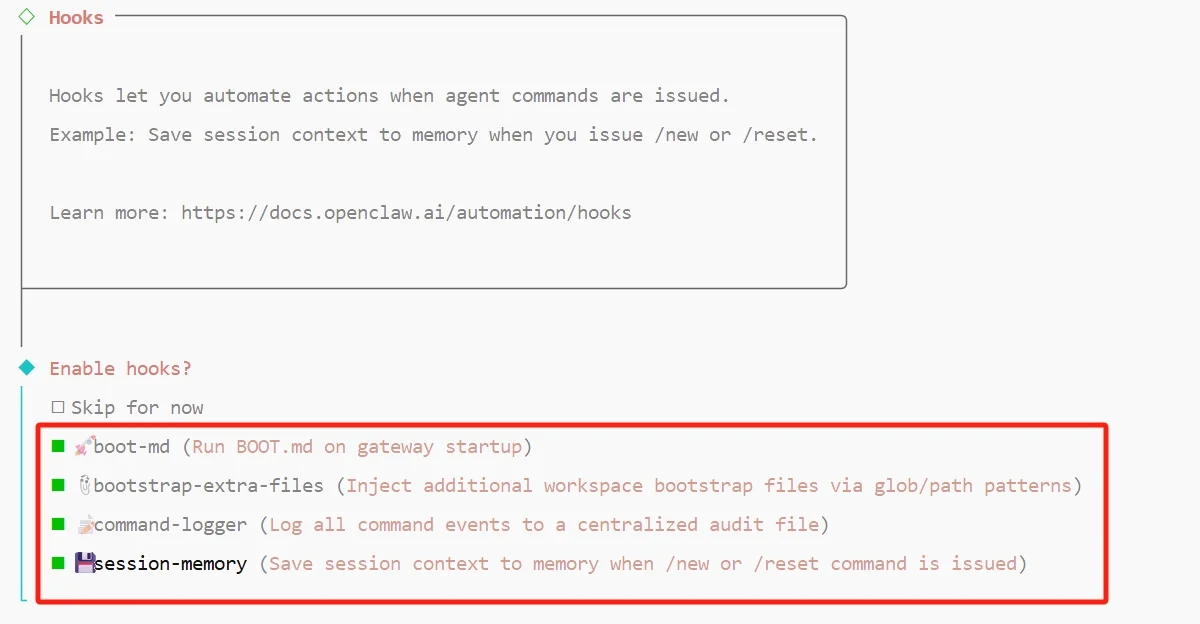
Hooks 是 OpenClaw 在会话生命周期中的自动化钩子,用于在特定时刻(如 OpenClaw 启动、收到 /new 或 /reset 命令时)自动触发动作。引导列出四个可启用的 Hook:
- boot-md:OpenClaw 启动时执行
BOOT.md中的预热逻辑 - bootstrap-extra-files:按文件路径规则注入额外的工作区引导文件
- command-logger:把所有命令事件写入操作日志
- session-memory:在
/new或/reset时把当前会话上下文存入记忆
全部启用即可,其中 session-memory 特别有用,它让管家在每次对话切换时自动归档关键信息,便于跨会话延续上下文。
- Hooks:管家在特定时刻(如 OpenClaw 启动、会话切换)自动触发的小脚本。
- session-memory:会话记忆 Hook,在对话切换时把上下文摘要写入持久存储,方便下次调用。
以上步骤完成后,引导脚本启动后台服务,显示完成信息以及后续操作的提示链接。至此,OpenClaw 已在云服务器上运行,后台监听中,默认模型已配置。管家目前仅能通过命令行交互,尚无对外消息入口。接下来装上微信插件,就能开始与管家对话。
